Оптимизация структуры БД
Для обеспечения оптимального доступа к информации в БД при проектировании физической и логической структуры БД следует учитывать ряд факторов. Перечислим некоторые из них.
Оптимальная структура индексов
От структуры индексов таблиц БД в огромной степени зависит эффективность выполнения запросов. При выполнении запросов InterBase сначала просматривает список индексов, определенных для таблиц, участвующих в запросе. Затем выбирается одна из двух схем выполнения запроса - использовать имеющиеся индексы или последовательно просмотреть таблицы. Оптимизатор InterBase стремится выполнить запрос с максимальным быстродействием и с минимальными накладными расходами. Он всегда оптимизирует запрос при его первом использовании, основываясь на текущем состоянии БД. Повторно параметрические запросы, у которых меняются только значения запросов, не оптимизируются.
Происходит лишь предварительное связывание формальных и фактических параметров, после чего запрос выполняется.
Хотя состояние БД может меняться и поэтому полностью предсказать, по какой схеме оптимизатор InterBase будет выполнять запрос, нельзя, существуют общие положения, которые следует учитывать при проектировании запросов.
Полезность" индексов
Эффективность использования индекса при поиске информации в таблице БД сильно зависит от того, построен ли индекс по уникальным значениям и, если нет, насколько отличаются данные, по которым он построен.
Пусть необходимо выбрать из таблицы RASHOD все записи о расходе товара за 10.01.1997, у которых количество расходуемого товара превышает 300 единиц:
SELECT * FROM RASHOD WHERE DAT_RASH = "10/01/1997" AND KOLVO > 300
При выполнении запроса InterBase определяет - есть ли индексы, построенные одновременно по столбцам DAT_RASH и KOLVO, столбцам KOLVO и DAT_RASH, или индексы, в которые указанные столбцы входят в качестве ведущих (например, индекс, построенный по столбцам DAT_RASH, KOLVO, TOVAR, но не индекс, построенный по столбцам DAT_RASH, TOVAR, KOLVO). При отсутствии таких индексов проверяется наличие индексов отдельно по столбцам DAT_RASH и KOLVO.
В случае отсутствия таких индексов поиск записей, удовлетворяющих запросу, осуществляется путем перебора всех записей в таблице, т.е. путем последовательного доступа, что обеспечивает наименьшую эффективность выполнения запроса. В случае нескольких индексов, по которым можно осуществить поиск (например, индекс по столбцам DATJR.ASH, KOLVO и по столбцам KOLVO, DAT_RASH), выбирается для использования тот, у которого выше показатель полезности индекса (selectivity).
Показатель полезности индекса
рассчитывается как число различающихся значений индексных полей внутри индекса, отнесенное к среднему количеству записей. Этот показатель рассчитывается при создании индекса. После внесения изменений в таблицу, по которой построен индекс, меняется степень отличия значений столбцов, по которым построен индекс. Поэтому рассчитанный показатель полезности может не отражать реального состояния индекса и значение показателя рекомендуется принудительно пересчитывать: время от времени - при внесении небольших изменений и всегда - при внесении существенных изменений. Пересчет реализуется операторомSET STATISTIC INDEX ИмяИндекса
Среднее количество записей -
показатель, который рассчитывается всякий раз при оптимизации запроса как количество страниц БД, занятых этой таблицей, деленное на максимальное число записей на странице. Уменьшение числа страниц, занятых БД, и уничтожение на них "дыр" ведут к уменьшению показателя среднего числа записей и, как следствие - к повышению показателя полезности индексов. Это еще один аргумент в пользу периодического сжатия БД путем создания резервной копии и восстановления из нее БД.Для участия в выполнении запроса выбираются индексы с максимальным показателем полезности. Такие индексы обеспечивают более быстрый поиск. Максимальным показателем полезности обладают уникальные индексы, т.е. индексы, построенные по определениям первичных и уникальных ключей.
Просмотр плана выполнения запросов
При выполнении запросов к БД в утилите WISQL установим режим показа плана выполнения запроса (выбрав элемент меню Session | Bas'ic Settings и отметив режим Display Query Plan). Тогда при выполнении запросов будет выводиться и план их выполнения. Под планом выполнения запроса понимается перечень индексов, используемых InterBase при выполнении запроса. Слово NATURAL означает последовательный перебор таблицы. Например,
SELECT RASHOD.*, TOVARY.ZENA
FROM RASHOD, TOVARY
WHERE RASHOD.TOVAR = TOVARY.TOVAR
PLAN JOIN (RASHOD NATURAL,TOVARY INDEX (RDB$PRIMARY8))
NRASH
DATRASH
KOLVO
TOVAR
POKUP ZENA
2
10-JAN-1997
20
Сахар
Лира, ТОО 4
3
10-JAN-1997
509
Сахар
<null> 4
4
10-JAN-1997
3000
Ставрида консерв.
Адмирал, АО 5
5
10-JAN-1997
4000
Кока-кола
Саяны, ИЧП 3
6
20-JAN-1997
30
Сахар
Саяны, ИЧП 4
7
20-JAN-1997
20
Кока-кола
<null> 3
8
20-JAN-1997
1000
Кока-кола
Адмирал, АО 3
1
10-JAN-1997
100
Кока-кола
Адмирал, АО 3
Для принудительного выполнения запроса по тому или иному плану, следует в операторе SELECT использовать предложение
PLAN <план выполнения_запроса>
< план выполнения запроса > =
[JOIN | [SORT] MERGE] (<элемент_плана> | < план _выполнения_запроса >
[, < элемент плана > I < план выполнения запроса > . . . ] )
<элемент_плана> = {таблица | алиас}
NATURAL | INDEX ( <индекс> [, < индекс >...]) I ORDER < индекс >
Синтаксис предложения PLAN относится как к единичной таблице БД, так и к нескольким таблицам. В последнем случае выполняется соединение таблиц для увеличения скорости выполнения запроса, что определяется использованием необязательного ключевого слова JOIN. В том случае, если не существует индексов, по которым данные таблицы могли бы быть соединены, для увеличения скорости выполнения запроса указывают ключевые слова SORT MERGE.
<элемент_плана>
является именем таблицы, в которой производится поиск данных. В том случае, если одна и та же таблица несколько раз участвует в запросе, для сокращения текста плана полезно использовать ее псевдоним, то есть обозначение, указываемое в предложении FROM после имени таблицы. Следующие ключевые слова определяют способ доступа к данным.NATURAL (по умолчанию) - указывает, что для поиска записей применяется последовательный доступ. Это единственный способ поиска записей в том случае, если нет подходящих индексов.
INDEX - указывает один или несколько индексов, которые должны использоваться для поиска записей, удовлетворяющих условию запроса.
ORDER - указывает, что <элемент_плана> должен быть отсортирован по указанному индексу.
Целесообразность создания индексов
Индексы необходимо создавать в случае, когда по столбцу или группе столбцов часто
• производится поиск в БД (столбец или группа столбцов часто перечисляются в предложении WHERE оператора SELECT);
• строятся объединения таблиц;
производится сортировка НД, возвращаемых в качестве результатов запросов к БД (т.е. столбец или столбцы часто используются в предложении ORDER BY оператора SELECT).
Не рекомендуется строить индексы по столбцам или группам столбцов, которые:
• редко используются для поиска, объединения и сортировки результатов запросов;
• содержат часто меняющиеся значения, что приводит к необходимости частого обновления индекса и способно существенно замедлить скорость работы с БД;
• содержат небольшое количество вариантов значения.
Частичное использование составного индекса
Если запросы часто используют для поиска одни и те же столбцы, следует построить по этим столбцам индекс (если это возможно), так, чтобы чаще используемые столбцы выступали в качестве ведущих полей индекса. Тогда при поиске может быть использована часть индексных полей.
Пример.
Пусть часто выполняются запросыSELECT * FROM SOME TABLE WHERE A = : ParamA AND В = :ParamB
SELECT * FROM SOME TABLE
WHERE A = : ParamA AND В = :ParamB AND С = :ParamC
SELECT * FROM SOME TABLE
WHERE A = : ParamA AND В = :ParamB AND С = :ParamC AND D = :ParamD
SELECT * FROM SOMETABLE
ORDER BY А,В
Тогда, построив индекс по столбцам А, В, С, D, мы можем с большой долей уверенности утверждать, что данный индекс будет использован при оптимизации всех четырех запросов. В первом случае будут использовано подмножество индекса, т.е. значения А, В; во втором - значения А, В, С, в третьем - А, В, С, D (то есть все значения индекса); в четвертом - А, В.
Следует помнить, что при использовании в запросах не всех столбцов из индекса, можно использовать только непрерывную последовательность столбцов, что важно для указания порядка сортировки в предложении ORDER BY. Например, если индекс построен по столбцам А, В, С, D, этот индекс не может использоваться для выполнения запросов
SELECT * FROM SOMETABLE ORDER BY А,С
SELECT * FROM SOMETABLE ORDER BY B,D
Порядок следования условий по столбцам в предложении WHERE оператора SELECT не важен (если условия объединены с помощью AND). Например, для выполнения следующих запросов может использоваться один и тот же индекс:
SELECT * FROM SOMETABLE WHERE A = 100 AND В = 200
SELECT * FROM SOMETABLE WHERE В = 200 AND A = 100
Однако при указании уровней сортировки в предложении ORDER BY оператора SELECT порядок следования столбцов является существенным. Например, для выполнения следующих запросов не может использоваться один и тот же индекс:
SELECT * FROM SOMETABLE ORDER BY А, В, С
SELECT * FROM SOMETABLE ORDER BY А, С, В
Многопоточность поиска по OR и IN
При частом использовании в условной части WHERE оператора SELECT нескольких столбцов, связанных между собой операцией "или" (OR):
SELECT * WHERE A = 100 OR В = 200 OR С = 300
вместо индекса по столбцам А, В, С лучше создать несколько индексов, построенных по каждому из этих полей, поскольку в противном случае будет осуществлен последовательный просмотр всей таблицы. Это неудивительно, так как индексно-последовательный доступ для индексов А, В, С может быть осуществлен только для столбца А; значения столбцов В и С в этом случае спонтанно разбросаны по индексу. Важно помнить, что при использовании оператора OR в условной части оператора SELECT каждая часть условия влечет за собой отдельное сканирование таблиц, участвующих в запросе. Так, например, при выполнении оператора SELECT с условной частью
WHERE А = 100 OR В = 200 OR С = 300
будет осуществлено три отдельных сканирования таблицы (таблиц) для поиска значений, удовлетворяющих условиям А = 100; В = 200; С = 300.
Отдельный поток поиска порождает и каждый элемент в списке IN. Например,
WHERE A IN (100,200,300)
интерпретируется как
WHERE А = 100 OR А = 200 OR A = 300.
Однако при указании диапазона BETWEEN
WHERE A BETWEEN 100 AND 300
этого не происходит. Поэтому там, где возможно, следует заменять IN на BETWEEN.
Уменьшение общего количества индексов
Следует стремиться к уменьшению количества индексов, поскольку при большом их количестве снижается скорость добавления, изменения и удаления записей в таблицах БД. Как правило, в БД определяется два вида индексов : индексы, фактически использующиеся запросами для доступа к данным, и индексы, введенные в БД для обеспечения ссылочной целостности между родительскими и дочерними таблицами БД. Если индексы не используются при доступе к данным, их следует удалять, а ссылочную целостность обеспечивать с использованием триггеров.
Оптимизация запросов
Оптимизация запросов к БД связана с построением адекватной запросам и оптимальной структуры индексов таблиц БД и оптимизацией собственно текстов запросов.
Минимизация соединений с БД
Для соединения с удаленной БД в клиентских Delphi-приложениях используется компонент TDatabase. Он служит для:
• создания постоянного соединения с БД;
• создания локального псевдонима БД;
• изменения параметров соединения, установленных для псевдонима БД (в утилите BDE Administrator);
• управления транзакциями.
Если не использовать компонент TDatabase, то соединение с БД может, в принципе, осуществлять каждый компонент типа "набор данных" (TTable, TQuery, TStoredProc). Однако следует помнить, что каждое соединение с БД потребляет системные ресурсы и их чрезмерный расход может сказаться на эффективности доступа к БД. Кроме того, при соединении с удаленной БД "напрямую", из компонентов типа "набор данных", невозможно изменять предустановленные параметры соединения.
Поэтому рекомендуется снижать число соединений с удаленной БД к минимуму, а в идеале - иметь одно соединение с каждой БД.
Использование TQuery
Хотя при доступе к таблицам БД может использоваться два компонента типа "набор данных" -TTable и TQuery, для доступа к удаленным данным рекомендуется использовать комнонент TQuery.
ПРИМЕЧАНИЕ.
Компонент TStoredProc используется только для работы с вызываемыми процедурами и не применяется для работы с процедурами выбора, которые также могут возвращать наборы данных. Для работы с процедурами выбора также используется компонент TQuery.Предпочтительность использования TQuery при доступе к удаленным данным определяется следующими причинами:
• при доступе к табличным данным компонент TTable считывает все записи удаленной таблицы, в то время как TQuery - ровно столько, сколько нужно для текущих целей визуализации, например, для заполнения сетки TDBGrid; при доступе к таблицам большого объема использование TTable может привести к существенным временным задержкам;
• компоненты TTable и TQuery имеют разную природу: TTable ориентирован на навигационный метод доступа к данным, что более характерно для работы с локальными СУБД; TQuery ориентирован на работу с множествами записей, что характерно при доступе к удаленным БД в архитектуре "клиент-сервер"; TTable позволяет обратиться к одной таблице БД, TQuery - к результатам выполнения запроса одновременно к нескольким ТБД; соответственно, подтверждение изменений данных в TTable осуществляется для каждой записи, что существенно увеличивает сетевой трафик; изменение данных при использовании TQuery может производиться сразу над множеством записей с использованием операторов INSERT, UPDATE, DELETE;
• при помощи компонента TQuery можно выполнять разнообразные SQL-операторы, как возвращающие НД (SELECT), так и не возвращающие его (INSERT, и т.д.).
Перенос тяжести вычислительной работы на сервер
При работе с удаленными БД следует стремиться перенести всю тяжесть вычислительной работы на сервер, по возможности оставив приложению клиента лишь работу по реализации интерфейса с пользователем, отсылки запросов к серверу и интерпретации полученных от него данных.
Не надо обращаться к серверу с запросом необоснованно большого объема данных, на которые приходится накладывать фильтры в самом клиентском приложении.
Следует максимально использовать возможности сервера, памятуя о том, что он может выполнять большинство требований приложения быстрее и оптимальнее и, кроме того, серверу не нужно пересылать данные самому себе по сети.
Реализуйте ограничения на значения вводимых пользователем данных при помощи аппарата ограничений БД (CONSTRAINTS), а ссылочную целостность - при помощи триггеров.
Запросы, требующие при своем выполнении ветвящихся или циклических алгоритмов, а также всевозможные вычисления значений, основанные на текущих данных из БД, реализуйте при помощи хранимых процедур.
Бизнес-правила, связанные с транзакционными изменениями ряда таблиц, реализуйте при помощи триггеров.
Получайте уникальные значения числовых полей при помощи генераторов.
Повторяющиеся действия, которые могут разделяться различными приложениями и использоваться в SQL-операторах, реализуйте при помощи функций, определенных пользователем (UDF).
Перенос тяжести вычислительной работы на сервер, во-первых, убыстряет работу клиентского приложения, а во-вторых, минимизирует возможность возникновения ошибок.
Оптимизация клиентских приложений
От того, каким образом организуется доступ к удаленной БД, во многом зависит, насколько эффективно будет работать с ней данное приложение.
Оптимизация работы с БД
Под оптимальной работой с БД обычно понимают создание таких условий, когда обеспечивается наибольшее быстродействие БД при минимально возможных затратах ресурсов.
Оптимизация зависит от многих факторов, которые можно разбить на три группы:
• оптимизация структуры БД;
оптимизация запросов;
• оптимизация клиентского приложения.
Такой важный фактор, как производительность сервера, не часто (к сожалению) может подвергаться воздействию со стороны разработчиков БД и приложений для работы с БД. Поэтому, декларировав известный факт, что чем мощнее аппаратура сервера, тем лучше, рассмотрим такие факторы, которые поддаются воздействию со стороны разработчиков и администраторов БД.
Соединение с сервером
Для соединения с сервером выберите элемент меню File \ Server Login, затем укажите имя сервера, протокол и введите имя пользователя и пароль (рис 38 1)
Соединение с БД
Для соединения с БД следует выбрать элемент меню File | Database Connect и указать имя БД (рис. 38.2).
Выбор текущего сервера и БД
Одновременно может быть установлено соединение с несколькими серверами и базами данных. Для выбора конкретного сервера или БД установите на них инверсную полосу в окне утилиты (рис. 38.3).
Разрыв соединения
Для разрыва соединения с БД выберите элемент меню File \ Database Disconnect
Для разрыва соединения с сервером выберите элемент меню File [ Server Logout При этом будут разорваны все соединения с БД этого сервера
Изменение конфигурации сервера
Описываемые ниже изменения может производить только пользователь SYSDBA (системный администратор). Выберите элемент меню Tasks \ Server Config. В окне IB Settings можно изменить значения следующих параметров-
Database Cache -
для каждой БД, с которой установлено соединение, задает размер буфера (кэша) в страницах. В этом кэше размещаются страницы БД. Увеличение размера кэша может существенно ускорить работу с БД, поскольку реально операции чтения/записи будут относиться не к физической БД на диске, а к кэшу в оперативной памяти. Перенос страниц из памяти в физическую БД проводится в фоновом режиме. Однако слишком большой размер кэша при наличии одновременно выполняющихся запросов ко многим БД может привести к нехватке памяти и замедлению работы. Чтобы определить реально необходимый размер кэша, следует умножить число страниц БД на объем страницы в килобайтах (эти параметры задаются при создании БД).Client map size
определяет размер буфера для каждого соединения с клиентом. По умолчанию равен 4 Кбайт, может изменяться в диапазоне 1...8 Кбайт. Потребность в изменении данного параметра может возникнуть при работе с BLOB-полями.На странице OS Settings можно (только системному администратору, пользователь SYSDBA) устанавливать значения следующих параметров:
Process Working Set -
определяет дополнительную память, резервируемую InterBase для своих нужд, совместно с буфером, размер которого задается параметром Database Cache; Minimum и Maximum определяют диапазон дополнительной памяти в страницах.Process Priority Class
определяет приоритет задач сервера по отношению к другим задачам, выполняющимся на данном компьютере. Установка в этом параметре значения High обоснована в следующих случаях:при работе InterBase на выделенном для этого компьютере в условиях отсутствия других приложений;
при наличии большого числа пользователей, активно читающих и записывающих информацию в БД.
Статистические данные непосредственно о БД
Для запуска процесса сбора статистики выберите элемент меню Tasks | Database Statistics. В появившемся текстовом окне (рис. 38.4) будет выдан статистический отчет.
Секция Database header page information содержит сведения из заголовочной страницы БД.
Flags -
указывает флаг БД. Некоторые значения:1 - БД является "зеркальной" копией основной БД;
2 - разрешен режим принудительной записи (forced writes), когда запись данньк производится в физической БД; при отмене этого режима запись производится в буфер, а потом в фоновом режиме (обычно при переполнении буфера) переносится на диск; при сбое системы данные из буфера могут быть потеряны, что чревато непредсказуемыми последствиями.
Checksum -
Контрольная сумма заголовка БД. Уникальное значение, которое вычисляется по всем данным в заголовке БД. Используется для анализа правильности данных в заголовке БД.Generation -
счетчик, который увеличивается на 1 при каждом обновлении данных в заголовке БД.Page size -
размер страницы БД в байтах.ODS version -
версия структуры БД на диске.Oldest transaction -
номер старейшей незавершенной транзакции (см. также Next transaction). Незавершенной считается транзакция, если она активна, отменена (rolled back) или зависла (in limbo, то есть во время ее действия и до применения к ней подтверждения или отката произошел сбой, и после него невозможно сказать, завершена транзакция или нет; такое возможно для транзакций, охватывающих БД, которые расположены на различных серверах).Oldest active -
старейшая активная транзакция.Next transaction -
номер, который будет присвоен следующей транзакции. При выполнении условия Next transaction - Oldest transaction > Sweep interval производится автоматическая чистка мусора в БД. Sweep interval (no умолчанию 20 000) - число транзакций, через которое происходит автоматическая чистка мусора.Sequence number -
номер первой страницы БД.Next attachment ID -
номер следующего соединения с БД.Number of cache buffers -
размер буфера в страницах БД.Next header page -
номер следующей страницы заголовка БД.Creation date -
дата создания БД.Attributes -
атрибуты БД.Секция Database file sequence описывает характеристики последовательности файлов, из которых состоит БД.
Секция Database log page information содержит информацию о страницах журнала БД (только для серверов NetWare).
Анализ БД
Выберите View | Database Analysis в окне Database Statistics. Вы получите информацию обо всех таблицах и индексах БД.
Принудительная сборка мусора
Для принудительной сборки мусора выберите элемент меню Maintenance \ Sweep. Необходимость сборки мусора обусловливается следующим. При чтении транзакцией записи, все старые версии этой записи, не использующиеся активными транзакциями, удаляются. Это касается только записей, созданных подтвержденными транзакциями. Версии, созданные транзакциями, впоследствии откатившимися (rolled back), а также старые версии записей, закрепленные за активными транзакциями, остаются в БД. Это сильно увеличивает объем БД и понижает быстродействие работы с ней. Поэтому в целях оптимизации используют сборку мусора (garbage collection).
Пример.
Извлечения из статистики БД до и после сборки мусора:
До сборки мусора:
Oldest transaction 2549
Oldest active 13438
Next transaction 13441
После сборки мусора:
Oldest transaction 13441
Oldest active 13441
Next transaction 13442
Изменение значения sweep interwal, использующегося для включения автоматической сборки мусора, может быть произведено в элементе меню Maintenance | Database Properties (рис. 38.5). Однако следует помнить о том обстоятельстве, что автоматическая сборка мусора может быть неэффективной, если в момент ее осуществления имеется много активных транзакций вследствие интенсивной работа клиентов с БД: в этом случае, во-первых, много версий записей, занятых активными транзакциями, не войдет в число "собранных" записей; во-вторых, сборка мусора существенно замедлит выполнение активных транзакций. Поэтому рекомендуется собирать мусор либо вручную при минимальном числе пользователей, либо при восстановлении БД (когда подключений к БД быть вообще не должно). Просмотреть активных пользователей можно, выбрав элемент меню Maintenance \ Database Connections (рис. 38.6).
Active Database Connections
Database с:\proiect\monitor\db\MON.gdb
User Name
SYSDBA
Переход в однопользовательский режим соединения с БД
Создание резервной копии может производиться без отключения других пользователей Однако следует помнить, что в этом случае в резервной копии будут сохранены все данные, измененные на момент создания резервной копии Поэтому резервное копирование обычно осуществляют в момент отсутствия соединений с БД со стороны пользователей Это бывает обычно в вечерние, ночные или утренние часы. Существующие соединения пользователей могут быть принудительно разорваны Для этого нужно выбрать элемент меню Maintenance \ Database Shutdown и в диалоговом окне (рис. 38 7) установить параметры принудительного разъединения.
Deny new connections while waiting -
все существующие соединения пользователей с БД должны завершить свои операции Если по истечении указанного ниже периода времени остались активные соединения с пользователями, БД не переводится в однопользовательский режим, необходимый для создания резервной копии.Deny new transactions while waiting - существующие транзакции должны завершиться (Server Manager ожидает их завершения). Старт новых транзакций блокируется Если по истечении указанного ниже периода времени остались активные транзакции, БД не переводится в однопользовательский режим.
Force shutdown after the time-out period -
активные транзакции могут выполняться в течение указанного ниже периода Если в конце данного периода остаются активные транзакции, они принудительно откатываются и затем все соединения с пользователями принудительно разрываютсяРезервное копирование БД
Для создания резервной копии БД следует выбрать элемент меню Tasks | Backup и в диалоговом окне (рис 38 8) указать путь к БД, которая должна служить источником для создания резервной копии, а также путь и имя файла резервной копии В окне Options указываются необязательные параметры резервного копирования БД
Transportable Format -
создание транспортного формата резервной копии в общем формате представления данных, что делает возможным перенесение БД в другие операционные среды, для которых существуют реализации InterBase.Back Up Metadata Only -
сохранять только метаданные, игнорируя страницы данных. Полезно в том случае, когда нужно создать заготовку пустой БД (например, при дистрибутировании разработанной программной системы).Disable Garbage Collection -
не производить сборку мусора при сохранении БД.Ignore Transaction in Limbo -
игнорировать при сохранении БД транзакции in limbo (транзакции, о которых нельзя сказать, завершились они или откатились; возникают при двухфазной фиксации транзакций для БД, расположенной на разных серверах, если операция подтверждена на одном сервере, а на другом в момент подтверждения транзакции произошел аппаратный сбой). Для восстановления транзакций in limbo перед созданием резервной копии следует выбрать элемент меню Maintenance \ Transaction Recovery.Ignore Checksums -
игнорировать неверные контрольные суммы заголовочных страниц БД, где хранится информация о БД, необходимая для соединения с нею; отключение данного режима (по умолчанию) предотвращает сохранение БД с разрушенной структурой.Verbose Output -
получение расширенного отчета (в отдельном окне) о ходе создания резервной копии БД.Восстановление БД из резервной копии
Для того чтобы восстановить БД из ранее сделанной резервной копии, необходимо выбрать в меню режим меню Tasks | Restore и затем в диалоговом окне указать путь и название резервной копии и БД, которая будет восстановлена (рис 38 9) В правой части диалогового окна параметр Page Size устанавливает размер страницы восстанавливаемой БД Там же могут быть установлены следующие параметры-
Replace Existing Database -
заменят существующую БД с тем же именем, если она расположена в том каталоге, куда должна помещаться восстанавливаемая БДCommit After Each Table -
подтверждать восстановление после каждой таблицы Это актуально в тех случаях, когда в резервной копии имеются разрушенные данные и следует восстанавливать не все из них.Restore Without Shadow -
при восстановлении БД не создавать теневой (зеркальной) копии БД, если для этой БД назначено автоматическое ведение теневой копии. Это может быть необходимо в случаях восстановления БД на сервере, который не поддерживает теневого копирования, восстанавливаемая БД сама является теневой копией БДПри этом в восстановленной БД будут уничтожены определения теневой БД, если восстановление БД, для которой ранее осуществлялось теневое копирование, осуществляется с включенным режимом Restore Without Shadow
Deactivate Indexes -
отключить восстановление индексов InterBase строит индексы после того, как БД восстановлена. Если в БД, служившей источником для создания резервной копии, существуют дублированные значения столбцов, по которым построены уникальные или первичные индексы, попытка перестройки индексов для восстановленной БД вызовет ошибку В этом случае следует отключить восстановление индексов и затем, используя утилиту WISQL, устранить дублирование значений. После этого можно активизировать индексы (SQL-оператор ALTER INDEX)Do Not Restore Validity Conditions -
не восстанавливать определения ограничений ссылочной целостности. Это важно в том случае, когда резервная копия БД содержит устаревшие ограничения ссылочной целостности, которые должны быть заменены новымиVerbose Output -
получение расширенного отчета (в отдельном окне) о ходе восстановления БД из резервной копииВ том случае, когда восстанавливаемая БД должна располагаться в нескольких физических файлах, следует нажать кнопку Multi-File и в окне диалога (рис 38.10) в поле File Path указать имя каждого файла БД и его размер в страницах в поле Sire Затем следует нажать кнопку Save Тогда имя файла и его размер появятся в списке File List Изменить характеристики фай па из списка можно после нажатия кнопки Modify Для удаления файла из списка используйте кнопку Delete
Создание резервной копии (сохранение) и восстановление БД
Сохранение БД может иметь своей целью
получение текущей резервной копии БД, которая может быть использована для восстановления БД в случае ее сбоя,
улучшение характеристик производительности при работе с БД, затем восстановленной из резервной копии, поскольку при сохранении/ восстановлении
для хранения таблиц выделяются непрерывные блоки страниц,
производится автоматическая сборка мусора,
получение копии многофайловой БД в одном файле
Принудительная запись на диск
Записи таблиц при добавлении или изменении их в БД могут помещаться в буфер или немедленно физически записываться на диск В первом случае записи из буфера физически записываются на диск после заполнения буфера
Режим накапливания изменений в буфере экономит время и улучшает быстродействие при работе с БД, поскольку достаточно медленное обращение к диску происходит реже Однако в случае сбоя данные из буфера теряются, не будучи записаны на диск, что способно серьезно нарушить целостность БД
Поэтому рекомендуется второй метод, метод немедленной (принудительной) записи на диск (forced writes) Этот режим установлен для сервера БД по умолчанию Отключить или повторно включить его можно в диалоговом окне установки свойств БД. Это окно вызывается при выборе элемента меню Maintenance \ Database Properties (отметка Enable Forced Writes)
Восстановление транзакций
В случае, если транзакция затрагивает БД, расположенные на разных серверах, подтверждение такой транзакции осуществляется в две фазы Все действия при этом выполняются автоматически и не требуют программирования При возникновении ошибки в ходе выполнения двухфазной фиксации транзакция считается потерянной и относительно нее сервер БД не может решить, закончилась она или откатилась
Для восстановления таких транзакций следует выбрать опцию меню Maintenance Transaction Recovery В диалоговом окне будут показаны в виде списка транзакции in limbo Они могут быть подтверждены или отменены Для каждой транзакции могут быть показаны все связанные с ней транзакции (путем выбора знака '+' слева от транзакции)
Регистрация новых пользователей
Регистрация новых пользователей может осуществляться администратором системы Для этого следует выбрать элемент меню Tas/:s | Us'er Security В появившемся окне будет указан список имен зарегистрированных на сервере пользователей (рис 38 11)

Рис 38.11 Регистрация пользователей
Добавление нового пользователя реализуется по нажатию кнопки Add User. В этом случае необходимо указать имя пользователя и пароль (рис.38.12). Они будут запрашиваться при доступе к БД.
Изменение реквизитов пользователя производится после нажатия кнопки Modify User, удаление - по нажатию кнопки Delete User.
Работа с утилитой InterBase Server Manager
Утилита InterBase Server Manager служит для .
управления сервером;
регистрации пользователей и установки для них прав доступа к тем или иными БД;
проверки целостности БД;
сохранения и восстановления БД;
сборки мусора;
восстановления транзакций in limbo (потерянных транзакций для БД. расположенных на разных серверах);
получения статистической информации.
Привилегии доступа по умолчанию
По умолчанию доступ к таблицам и хранимым процедурам имеет только тот пользователь, который их создал. Кроме того, системный администратор имеет доступ ко всем компонентам БД.
Виды привилегий
Ниже перечислены виды привилегий и ключевые слова в операторе GRANT, соответствующие этим привилегиям.
Ключевое слово
Вид привилегии доступа
ALL
Выполнение операторов SELECT, DELETE, INSERT, UPDATE. EXECUTE
SELECT
Выполнение оператора SELECT
DELETE
Выполнение оператора DELETE
INSERT
Выполнение оператора INSERT
UPDATE
Выполнение оператора UPDATE
EXECUTE
Выполнение оператора EXECUTE (обращение к хранимой процедуре)
Минимальный состав параметров при предоставлении привилегий доступа к таблице БД
Для предоставления пользователю привилегии доступа к таблице в операторе GRANT необходимо указать как минимум следующие параметры:
ключевое слово, обозначающее вид привилегии доступа;
имя таблицы;
имя пользователя.
Например,
предоставить пользователю PASHA привилегию на выполнение поиска данных в таблице ТО VARY:GRANT SELECT ON TOVARY TO PASHA
Предоставление нескольких привилегий
Чтобы в одном операторе GRANT предоставить пользователю не одну, а несколько привилегий, следует привести список этих привилегий: GRANT SELECT, INSERT ON TOVARY TO DIMA
Словом ALL обозначается предоставление пользователю всех привилегий, то есть права считывания, добавления, изменения и удаления: GRANT ALL ON RASHOD TO PASHA
Предоставление привилегий нескольким пользователям
Если необходимо предоставить одну или несколько привилегий ряду пользователей, можно выполнить оператор GRANT для каждого пользователя, или указать список пользователей в одном операторе GRANT:
GRANT SELECT, INSERT, UPDATE ON RASHOD TO PASHA, DIMA
Назначение привилегий всем пользователям
В случае, если определенный вид привилегий по доступу к таблице должен быть назначен всем пользователям, в операторе GRANT указывают ключевое слово PUBLIC вместо списка имен пользователей:
GRANT SELECT, INSERT, UPDATE ON RASHOD TO PUBLIC
Установка привилегий доступа к отдельным столбцам таблицы
Привилегия на изменения определенных (не всех) столбцов таблицы также может быть указана в операторе GRANT для отдельных пользователей. В этом случае имена столбцов перечисляются в скобках после ключевого слова UPDATE: GRANT UPDATE (DAT_RASH, TOVAR, KOLVO) ON RASHOD TO DIMA
Предоставление пользователю права назначать привилегии другим пользователям
Если в операторе GRANT при предоставлении пользователю привилегии доступа к таблице указать необязательный параметр WITH GRANT OPTION, данный пользователь получит право назначать ту же привилегию другим пользователям. Например, после выполнения оператора
GRANT DELETE ON RASHOD TO PASHA WITH GRANT OPTION
пользователь PASHA получит право предоставлять привилегию удаления из таблицы RASHOD другим пользователям.
Назначение привилегий вызова хранимых процедур
При назначении привилегии вызова хранимой процедуры оператор GRANT имеет следующий формат:
GRANT EXECUTE ON PROCEDURE ИмяПроцедуры ТО <список_пользователей>
Например,
следующий оператор GRANT предоставляет право вызова процедуры MAX_VALUE:GRANT EXECUTE ON PROCEDURE MAX_VALUE TO PASHA
Назначение процедуре прав доступа к таблице
Если хранимая процедура выполняет какие-либо действия над таблицей SOMETABLE, а пользователь, имеющий право вызывать эту процедуру, не имеет прав доступа к этой таблице, следует указать права доступа к ней для самой процедуры:
GRANT SELECT ON SOMETABLE TO PROCEDURE SOMEPROC
Ликвидация привилегий
Ликвидация ранее выданных пользователю привилегий осуществляется при помощи оператора REVOKE. Его формат:
REVOKE [GRANT OPTION FOR]{
{ALL [PRIVILEGES] | SELECT | DELETE | INSERT
I UPDATE [(столбец [.столбец ...])]}
ON [TABLE] {ИмяТаблицы | ИмяПросмотра}
FROM {<объект> | <список пользователей>}
I EXECUTE ON PROCEDURE ИмяПроцедуры
FROM {<объект> | < список_пользователей >}
};
где все параметры идентичны по содержанию параметрам оператора GRANT, за исключением параметра
GRANT OPTION FOR -
удаляет право выдачи привилегий у пользователей из <списка_пользователей>. При этом <объект> не указывается.Привилегию может ликвидировать только тот, кто ее выдал. Если пользователь лишается привилегии определенного вида, назначенные ему привилегии всех остальных видов остаются в его собственности. Например:
GRANT ALL ON RASHOD TO DIMA
REVOKE INSERT ON RASHOD FROM DIMA
После выполнения REVOKE пользователь DIMA будет обладать правами изменения (UPDATE), удаления (DELETE) и выборки данных (SELECT) из таблицы RASHOD.
Лишение пользователя права назначать привилегии другим пользователям ведет к утрате данной привилегии всеми пользователями, которым он успел ее назначить. Привилегии, установленные для всех пользователей (PUBLIC), отнимаются также у всех пользователей (PUBLIC).
Установка привилегий доступа
Привилегия доступа - возможность определенного пользователя выполнять определенный вид действий над определенными таблицами базы данных. Привилегии доступа могут устанавливаться как системным администратором (пользователем с именем SYSDBA), так и пользователем, которому системный администратор предоставил такое право.
Установка привилегий производится оператором GRANT. Его формат:
GRANT{
{ALL [PRIVILEGES] I SELECT | DELETE I INSERT
I UPDATE [(столбец [.столбец ...])]}
ON [TABLE] {ИмяТаблицы I ИмяПросмотра}
TO {<объект> I <список_пользователей>}
I EXECUTE ON PROCEDURE procname
TO {<объект > < список_пользователей>}
};
<объект > = PROCEDURE ИмяПРоцедуры | TRIGGER ИмяТриггера |
VIEW ИмяПросмотра | [USER] ИмяПользователя |
PUBLIC [, <объект>]
< список пользователей > = [USER] ИмяПользователя[, [USER]
ИмяПользователя...] [WITH GRANT OPTION]
А) б)
Рис 332 а) до подтверждения изменений (UpdateAction = uaFail). б) после подтверждения изменений, открытия и закрытия НД "Товары " (UpdateAction = uaFail)
• UpdateAction = uaAbort.
Как показано на рис.33.3.а) и б), в режиме uaAbort результаты кэшированных изменений полностью отменены:
Рис 33.3 а) до подтверждения изменений (Update Action =uaAbort), б) noc-ie подтверждения изменений, открытия и закрытия НД "Товары" (UpdateAclion = uaAbort)
UpdateAction = uaSkip.
Как показано на рис.34.а) и б), в режиме uaSkip результаты кэшированных изменений отменены частично: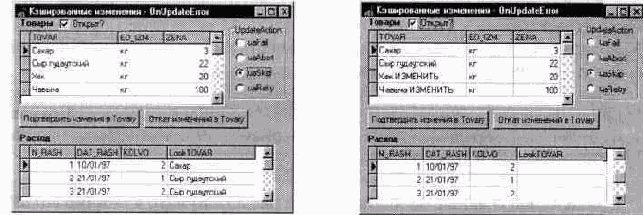
Рис 33.5. а) до подтверждения изменений (UpdateAction = uaRetry), 6) после подтверждения изменений, открытия и закрытия НД "Товары" (UpdateAction = uaRetry)
Причина зависания проста: при UpdateAction = uaRetry происходит попытка заново подтвердить квитированные изменения для записи, на которой произошла ошибка; однако поскольку значение поля "Товар" не изменилось, повторная попытка вызовет ошибку, для которой назначено действие новой попытки подтверждения, и т.д.
Введем в обработчик события OnUpdateError для режима UpdateAction = uaRetry возврат к старому значению поля "Товар" для записей, на которых попытка подтверждения изменений вызывает ошибку:
procedure TForm1.TovaryUpdateError(DataSet: TDataSet;
E: EDatabaseError; UpdateKind: TUpdateKind;
var UpdateAction: TUpdateAction);
begin
CASE RadioGroup1.ItemIndex OF
0 : UpdateAction := uaFail;
1 : UpdateAction := uaAbort;
2 : UpdateAction := uaSkip;
3 : begin
Tovary.FieldByName('Tovar').NewValue :=Tovary.FieldByName('Tovar').OldValue;
UpdateAction := uaRetry;
end;
END;//case
end;
Тогда обработчик OnUpdateError будет действовать, как если бы было установлено UpdateAction = uaSkip (рис. ЗЗ.6.а) и б)).

Рис 33.6 а) до подтверждения изменений (UpdateAction = uaRetry) с откатом ошибочных записей к старому значению, б) после подтверждения изменений, открытия и закрытия НД "Товары" (UpdateAction = uaRetry) с откатом
ошибочных записей к старому значению
ДaтаDelphi =ДатаInterBase.Days -15018 +ДamaInlerBase.MSec/(MSecsPerDay * 10);
где константа MSecsPerDay определена в Delphi как число миллисекунд в сутках.
в котором будет храниться создаваемая
19. Создание базы данных
19.1. Оператор CREATE DATABASE
Для создания БД используется оператор
CREATE {DATABASE SCHEMA} "<имя_файла>" [USER "имя_пользователя" [PASSWORD "пароль"]]
[PAGE_SIZE [=] целое] [LENGTH [=] целое [PAGE[S]]] [DEFAULT CHARACTER SET набор_символов]
[<вторичный_файл>]; <вторичный_файл> = FILE "<имя_файла>" [<файлов_информ>] [<вторичный_файл>]
<файлов_информ> = LENGTH [=] целое [PAGE[S]] | STARTING [AT [PAGE]] целое [<файлов_информ>]
| Аргумент | Описание |
| "<имя_фаила > " | Указывает спецификации файла, в котором будет храниться создаваемая БД Эти спецификации зависят от платформы |
| USER "имя_пользователя" | Имя пользователя, которое вместе с паролем, определяемым PASSWORD, проверяется при соединении пользователя с сервером, на котором расположена БД |
| PASSWORD "пароль" | Пароль, который вместе с именем пользователя проверяется при соединении пользователя с сервером |
| PAGESIZE [=] целoe | Размер страницы БД в байтах Допустимые размеры" 1024 (по умолчанию), 2048, 4096 или 8192 |
|
DEFAULТ СНАRACTER SET набор_символов |
Определяет набор символов, применимый в БД Если не указан, по умолчанию берется NONE. |
| FILE "<имя_файла>" | Имя одного или нескольких файлов, в которых будет располагаться БД |
| STARTING [AT [PAGE]] | Если БД располагается в нескольких файлах, это предложение позволяет определить, с какой страницы БД располагается в указанном файле. |
| LENGTH [=] целое [PAGE[S]] | Длина файла в страницах По умолчанию 75 страниц Минимум 50 страниц Максимум ограничен фактически имеющимся дисковым пространством |
При добавлении в БД записей, она увеличивается в объеме. Если нет никаких ограничений на размер БД, с теоретической точки зрения размер файла, в котором БД хранится, ограничен лишь объемом диска. Однако бывает необходимо, чтобы физический размер файла БД был фиксирован. Подобная необходимость может возникать в условиях ограничений на доступное дисковое пространство. В этом случае БД хранится не в одном файле, а в нескольких, а сами файлы могут располагаться на физически разных носителях. Самый первый файл БД называется первичньш, остальные - вторичными. Предложение STARTING AT [PAGE] указывает, с какой страницы начинается тот или иной вторичный файл. Предложение "LENGTH = целое" указывает длину того или иного файла. Например:
CREATE DATABASE "D:\BD\SKLAD.GDB"
FILE "D:\BD\SKLAD.GD1" STARTING AT PAGE 1001
LENGTH 500
FILE "D:\BD\SKLAD.GD2"
Здесь определяется БД "D:\BD\SKLAD.GDB", состоящая из 3 файлов: первичного "D:\BD\SKLAD.GDB" (длиной 1000 страниц), "D:\BD\SKLAD.GD1" длиной 500 страниц и "D:\BD\SKLAD.GD2" неопределенной длины.Если для вторичного файла не объявлена длина,следует указывать, с какой страницы он должен начинаться.
19.3. Определение пароля
Пароль при создании БД указывается для того, чтобы сервер смог идентифицировать пользователя по паре значений "имя пользователя -пароль": CREATE DATABASE "D:\BD\SKLAD.GDB" USER "XXX" PASSWORD "YYY" Эти имя и пароль принадлежат пользователю, создающему БД, и служат именно для идентификации пользователя. Не следует путать указываемые здесь имя пользователя и пароль с правами доступа к самой БД.
19.4. Указание размера страницы БД
Размер страницы указывается в байтах и может быть 1024, 2048,4096 или 8192 байт, например:
CREATE DATABASE "BAZA.GDB" PAGE_SIZE 4096;
Увеличение размера страницы может привести к ускорению работы с БД, поскольку:
уменьшается глубина индексов (depth, число шагов, за которое при помощи индекса будут найдены требуемые записи);
уменьшается число операций чтения при считывании длинных записей, поскольку за одну операцию чтения всегда считывается одна страница, запись, расположенная на одной странице, будет считана за один раз;
при малом объеме страницы запись располагается на нескольких страницах и соответственно считывается за несколько операций чтения.
Увеличение размера страницы не оправдано в том случае, если запросы на чтение к БД в основном возвращают небольшое число записей, не занимающих всю страницу. Поскольку за операцию чтения считывается одна страница БД, будет считываться много лишних записей.
19.5. Указание национальной кодировки символов, принимаемой по умолчанию
Для символьных столбцов в составе таблиц БД используются различные национальные кодировки. При создании БД национальный набор символов устанавливается предложением
DEFAULT CHARACTER SET набор_символов
Например, CREATE DATABASE "BAZA.GDB" ... DEFAULT CHARACTER SET WIN1251;
В дальнейшем всем создаваемым символьным столбцам таблиц БД (типы CHAR, VARCHAR) ставится в соответствие указанный набор_символов, например объявление в одной из таблиц базы данных BAZA.GDB столбца FAMILIA VARCHAR(25); интерпретируется как объявление FAMILIA VARCHAR(25) CHARACTER SET WIN1251; Изменить кодировку, принятую для БД по умолчанию, можно при определении конкретных доменов и столбцов.
Для БД, в которых столбцы будут хранить русские слова, рекомендуется кодировка WIN1251. К сожалению, на уровне создания БД невозможно установить по умолчанию порядок сортировки символов (collation order). Его определяют при объявлении доменов и отдельных столбцов (см. соответствующие разделы). Для получения списка доступных кодировок обратитесь к встроенной системе помощи InterBase.
в состав первичного или уникального
30. Использование генераторов
Часто в состав первичного или уникального ключа входят цифровые поля, значения которых должны быть уникальны, то есть не повторяться ни в какой другой записи таблицы. В одних случаях такое значение является семантически значимым и формируется пользователем по определенному алгоритму -например, номер лицевого счета в банке. В других случаях лучше предоставить выработку такого значения приложению или серверу БД.
Для локальных СУБД (например, Paradox) для названной цели применяются автоинкрементные поля. При добавлении новой записи BDE автоматически устанавливает значение автоинкрементного поля так, чтобы оно было уникальным и не совпадало со значением данного автоинкрементного поля в других записях таблицы - не только существующих, но и удаленных. Иными словами, ранее использовавшееся значение автоинкрементного поля, даже если оно освободилось в результате удаления записи, никогда не назначается вновь. Изменить значение автоинкрементного поля нельзя.
В InterBase отсутствует аппарат автоинкрементных столбцов. Вместо этого для установки уникальных значений столбцов можно использовать аппарат генераторов.
Генератором называется хранимый на сервере БД механизм, возвращающий уникальные значения, никогда не совпадающие со значениями, выданными данным генератором в прошлом.
Для создания генератора используется оператор CREATE GENERATOR ИмяГенератора;
Для генератора необходимо установить стартовое значение при помощи оператора
SET GENERATOR ИмяГенератора ТО СтартовоеЗначение;
При этом СтартовоеЗначение должно быть целочисленным. Для получения уникального значения к генератору можно обратиться с помощью функции GEN_ID (ИмяГенератора, шаг);
Эта функция возвращает увеличенное на шаг предыдущее значение, выданное генератором (или увеличенное на шаг стартовое значение, если ранее обращений к генератору не было).
Значение шага должно принадлежать диапазону -231...+231 -1.
ЗАМЕЧАНИЕ.
Не рекомендуется переустанавливать стартовое значение генератора или менять шаг при разных обращениях к GEN_ID. В противном случае генератор может выдать неуникальное значение и, как следствие, будет возбуждено исключение "Дублирование первичного или уникального ключа" при попытке запоминания новой записи в ТБД. Пример.
Пусть в БД определен генератор, возвращающий уникальное значение для столбца N_RASH в таблице RASHOD: CREATE GENERATOR RASHOD_N_RASH;
SET GENERATOR RASHOD_N_RASH TO 20;
Обращение к генератору непосредственно из оператора INSERT:
INSERT INTO RASHOD (N_RASH, DAT_RASH, KOLVO, TOVAR, POKUP)
VALUES(GEN_ID(RASHOD_N_RASH,1),"10-JAN-1997",100,"Сахар", "Лира, ТОО")
Присваивание ключевому столбцу уникального значения может быть реализовано через триггер, вызываемый перед запоминанием новой записи в БД:
CREATE TRIGGER BI_RASHOD FOR RASHOD
ACTIVE
BEFORE INSERT
AS
BEGIN
NEW.N_RASH = GEN_ID(RASHOD_N_RASH,1);
END
При этом в клиентском приложении, реализующем добавление новых записей в таблицу, столбец с уникальными значениями (в нашем случае N_RASH) в программе не заполняется и оператор INSERT имеет вид
INSERT INTO RASHOD (DAT_RASH, KOLVO, TOVAR, POKUP)
VALUES(:DAT_RASH, :KOLVO, :TOVAR, :POKUP)
Как можно заметить, столбец N_RASH в операторе не упоминается: все необходимые действия по заполнению этого столбца уникальным значением выполняет триггер BI_RASHOD.
В ряде случаев для доступа к содержимому таблиц удаленных БД в клиентских приложениях, разработанных с помощью Delphi, используют компонент TTable, который применяется для добавления, удаления и корректировки данных в этих таблицах. Здесь использование триггера может натолкнуться на неожиданное препятствие: при добавлении записи (метод Post компонента TTable) BDE отслеживает адекватность введенных значений столбцов добавляемой записи наложенным на эти столбцы ограничениям. Такой анализ осуществляется при выполнении метода Post в клиентском приложении (и, стало быть, до активизации триггера на сервере БД). При этом столбец с уникальным значением не заполнен, что с точки зрения BDE есть ошибка (поскольку данный столбец описан при создании с атрибутом NOT NULL, что обязательно для всех столбцов, входящих в первичный или просто уникальный ключ).
"Обмануть" BDE можно, присваивая столбцу N_RASH любое значение, которое затем будет заменяться триггером на значение, полученное при помощи функции GEN_ID. Однако более корректным будет в данном случае использование не триггера, а процедуры:
CREATE PROCEDURE GET_N_RASH
RETURNS (NR INTEGER)
AS
BEGIN
NR = GEN_ID(RASHOD_N_RASH,1) ;
END
При добавлении новой записи в таблицу в клиентском приложении вызов этой процедуры реализуется при помощи компонента TStoredProc, непосредственно после перевода компонента TTable в состояние dslnsert:
procedure TForm1.RashodTableAfterInsert(DataSet: TDataSet) ;
begin
StoredProc1.Close;
StoredProc1.ExecProc;
RashodTable.FieldByName('N_RASH').Value := StoredProc1.ParamByName('NR').Value;
StoredProc1.Close;
end;
Заметим, что приведенные выше действия могут быть также реализованы в обработчике события OnNewRecord компонента TTable.
Добавление нового столбца в таблицу БД
ALTER TABLE <имя таблицы> ADD Определения столбца>;
Добавление новых ограничений целостности
ALTER TABLE <имя таблицы> ADD [CONSTRAINT <имя ограничения>] Определения целостности>;
Добавление записей
INSERT INTO <объект> [(столбец! [, столбец2 ...])]
{VALUES (<значение1> [, <значение2> ...]) I <оператор SELECT> }
Firma
Дальнейшие действия BDE зависят от значения свойства UpdateMode набора данных.
При значении WhereAll обновления, сделанные пользователем В, будут отклонены и запись останется в том виде, в который она перешла после завершения транзакции пользователем А.
При значении WhereKeyOnly BDE будет идентифицировать в ТБД ту запись, которую нужно обновить, по значению индексного поля (полей). Пусть такое поле в данном случае Firma. Пользователь А не изменял значение этого поля -как было 'Янтарь', так и осталось. Поэтому обновление записи для пользователя В будет разрешено. В результате запись, о которой идет речь, будет в ТБД иметь вид то есть станет недостоверной.
При значении WhereChanged идентификация в ТБД записи, которая должна быть замещена, ведется на соответствие ключевого поля и поля, которое изменено. В данном случае это поля Firma и Doljnost. Поскольку пользователь А не менял этих полей, запись будет найдена и данные в ТБД вновь окажутся недостоверными.