Обзор

Содержание урока 11:
Обзор
Что такое мультимедиа
Мультимедиа в Delphi
Компонент TMediaPlayer
Два вида программ, использующих мультимедиа
Пример программы с мультимедиа ex11.zip
Обзор
Delphi позволяет легко и просто включать в программу такие мультимедийные объекты, как звуки, видео и музыку. В данном уроке обсуждается, как это сделать, используя встроенный в Delphi компонент TMediaPlayer. Подробно рассматриваются управление этим компонентом в программе и получение информации о текущем состоянии. Что такое мультимедиа
Точного определения, что же это такое, нет. Но в данный момент и в данном месте, наверное, лучше дать по-возможности наиболее общее определение и сказать, что “мультимедиа” - это термин относящийся к почти всем формам анимации, звукам, видео, которые используются на компьютере.
Давая такое общее определение, нужно сказать, что в данном уроке мы имеем дело с подмножеством мультимедиа, которое включает:
1. Показ видео в формате Microsoft's Video for Windows (AVI).
2. Воспроизведение звуков и музыки из MIDI и WAVE файлов.
Данную задачу можно выполнить с помощью динамической библиотеки Microsoft Multimedia Extensions для Windows (MMSYSTEM.DLL), методы которой инкапсулированы в компоненте TMediaPlay, находящийся на странице System Палитры Компонент Delphi.
Для проигрывания файлов мультимедиа может потребоваться наличие некоторого оборудования и программного обеспечения. Так для воспроизведения звуков нужна звуковая карта. Для воспроизведения AVI в Windows 3.1 (или WFW) требуется установить ПО Microsoft Video.
Мультимедиа в Delphi
В Delphi есть компонент TMediaPlayer, который дает Вам доступ ко всем основным возможностям программирования мультимедиа. Данный компонент очень прост в использовании. Фактически, он настолько прост, что многим начинающим программистам будет проще создать свою первую программу, проигрывающую видео или музыку, нежели показывающую классическую надпись "Hello World".
Простоту использования можно воспринимать двояко:
· С одной стороны - это дает возможность любому создавать мультимедиа приложения.
· С другой стороны, можно обнаружить, что в компоненте реализованы не все возможности. Если Вы захотите использовать низкоуровневые функции, то придется копаться достаточно глубоко, используя язык Delphi.
В данном уроке не описываются подробности внутренних вызовов мультимедийных функций при работе компонента. Все что нужно знать - это то, что компонент называется TMediaPlayer, и что он дает доступ к набору подпрограмм, созданных Microsoft и называемых Media Control Interface (MCI). Эти подпрограммы дают программисту простой доступ к широкому кругу устройств мультимедиа. Собственно работа с TMediaPlayer интуитивно понятна и очевидна. Компонент TMediaPlayer Для начала давайте создадим новый проект, затем поместим компонент TMediaPlayer (стр. System Палитры) на форму, как показано на рис.1.

Рис.1: Компонент TMediaPlayer на форме.
Компонент TMediaPlayer оформлен, как панель управления устройством с кнопками. Как и на магнитофоне, здесь есть кнопки “воспроизведение”, “перемотка”, “запись” и др.
Поместив компонент на форму, Вы увидите, что Инспектор Объектов содержит свойство "FileName" (см. рис.2). Щелкните дважды
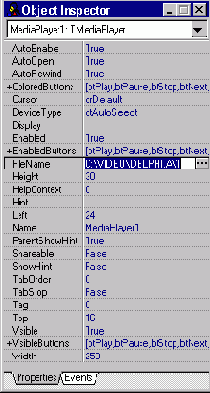
Рис.2: Свойства TMediaPlayer в Инспекторе Объектов
на этом свойстве и выберите имя файла с расширением AVI, WAV или
MID. На рис.2 выбран AVI файл DELPHI.AVI. Далее нужно установить свойство AutoOpen в True.
После выполнения этих шагов программа готова к запуску. Запустив программу, нажмите зеленую кнопку “воспроизведение” (крайняя слева) и Вы увидите видеоролик (если выбрали AVI) или услышите звук (если выбрали WAV или MID). Если этого не произошло или появилось сообщение об ошибке, то возможны два варианта: Вы ввели неправильное имя файла. Вы не настроили правильным образом мультимедиа в Windows. Это означает, что либо у Вас нет соответствующего ”железа”, либо не установлены нужные драйверы. Установка и настройка драйверов производится в Control Panel, требования к “железу” приводятся в любой книге по мультимедиа (нужна звуковая карта, например совместимая с Sound Blaster).
Итак, Вы имеете возможность проигрывать AVI, MIDI и WAVE файлы просто указывая имя файла. Еще одно важное свойство компонента TMediaPlayer - Display. Изначально оно не заполнено и видео воспроизводится в отдельном окошке. Однако, в качестве экрана для показа ролика можно использовать, например, панель. На форму нужно поместить компонент TPanel, убрать текст из св-ва Caption. Далее, для TMediaPlayer, в свойстве Display выбрать из списка Panel1. После этого надо запустить программу и нажать кнопку “воспроизведение” (см. рис.3)

Рис.3: Воспроизведение AVI на панели.
Два вида программ мультимедиа
· Иногда приходится предоставлять пользователям простой путь для проигрывания максимально широкого круга файлов. Это означает, что Вам нужно будет дать пользователю доступ к жесткому диску или CD-ROM, и затем позволить ему выбрать и воспроизвести подходящий файл. В этом случае, на форме обычно располагается TMediaPlayer, предоставляющий возможность управления воспроизведением.
· Иногда программист может захотеть скрыть от пользователя существование компонента TMediaPlayer. То есть, воспроизвести звук или видео без того, чтобы пользователь заботился об их источнике. В частности, звук может быть частью презентации. Например, показ какого-нибудь графика на экране может сопровождаться объяснением, записанным в WAV файл. В течении презентации пользователь даже не знает о существовании TMediaPlayer. Он работает в фоновом режиме. Для этого компонент делается невидимым (Visible = False) и управляется программно. Пример программы с мультимедиа В данной главе мы рассмотрим пример построения приложения с мультимедиа первого типа. Создайте новый проект (File | New Project). Поместите TMediaPlayer на форму; поместите компоненты TFileListBox, TDirectoryListBox, TDriveComboBox, TFilterComboBox для выбора файла. В свойстве FileList для DirectoryListBox1 и FilterComboBox1 поставьте FileListBox1. В св-ве DirList для DriveComboBox1 поставьте DirectoryListBox1. В св-ве Filter для FilterComboBox1 укажите требуемые расширения файлов:
AVI File(*.avi)|*.avi
WAVE File(*.wav)|*.wav
MIDI file(*.MID)|*.mid
Пусть по двойному щелчку мышкой в FileListBox1 выбранный файл будет воспроизводиться. В обработчике события OnDblClick для FileListBox1 укажите
Procedure TForm1.FileListBox1DblClick(Sender:TObject);
begin
with MediaPlayer1 do
begin
Close;
FileName:=FileListBox1.FileName;
Open;
Play;
end;
end;
Внешний вид формы представлен на рис.4

Рис.4: Начальный вид проекта
Сохраните проект, запустите его, выберите нужный файл и дважды щелкните на него мышкой. MediaPlayer должен воспроизвести этот файл в отдельном окне.
Как уже говорилось выше, видеоролик можно воспроизводить внутри формы, например, на панели. Давайте слегка модифицируем проект и добавим туда панель TPanel (см. рис.5). В св-ве Display для MediaPlayer1 укажите Panel1. Нужно убрать надпись с панели (Caption)
и св-во BevelOuter = bvNone. Чтобы переключаться при воспроизведении с окна на панель - поместите TСheckBox на форму и в обработчике события OnClick для него запишите:
procedure TForm1.CheckBox1Click(Sender: TObject);
var
Start_From : Longint;
begin
with MediaPlayer1 do begin
if FileName='' then Exit;
Start_From:=Position;
Close;
Panel1.Refresh;
if CheckBox1.Checked then
Display:=Panel1
else
Display:=NIL;
Open;
Position:=Start_From;
Play;
end;
end;
Запустите проект и воспроизведите видеоролик. Пощелкайте мышкой на CheckBox.

Во время выполнения программы может потребоваться отобразить текущее состояние объекта MediaPlayer и самого ролика (время, прошедшее с начала воспроизведения, длину ролика). Для этого у объекта TMediaPlayer есть соответствующие свойства и события: Length, Position, OnNotify и др. Давайте добавим в проект прогресс-индикатор (TGauge), который отобразит в процентах, сколько прошло времени (см. рис.6). Для обновления показаний индикатора можно воспользоваться таймером. Поместите на форму объект TTimer, установите для него Interval = 100 (100 миллисекунд). В обработчике события OnTimer нужно записать:
procedure TForm1.Timer1Timer(Sender: TObject);
begin
with MediaPlayer1 do
if FileName<>'' then
Gauge1.Progress:=Round(100*Position/Length);
end;
Запустите проект, выберите файл (AVI) и щелкните на нем два раза мышкой. При воспроизведении ролика прогресс-индикатор должен отображать процент, соответствующий прошедшему времени (см. рис.6).

В данной статье приводятся основные

Содержание урока 12:
Обзор
Основы DDE
Использование DDE
DDE-серверы
DDE-клиенты
Управление ReportSmith по DDE
ex12.zip
Обзор
В данной статье приводятся основные факты о DDEML и показывается, как можно использовать DDE в программе. Предмет данной статьи технически сложен, однако библиотека Delphi упрощает наиболее трудные аспекты программирования DDE .
В статье предполагается, что читатель может знать очень мало о предмете. Цель статьи - научить его использовать концепцию DDE при создании приложений в среде Delphi. Основы DDE
Аббревиатура DDEML обозначает Dynamic Data Exchange Management Library (библиотека управления динамическим обменом данными). DDEML это надстройка над сложной системой сообщений, называемой Dynamic Data Exchange (DDE). Библиотека, содержащая DDE била разработана для усиления возможностей первоначальной системы сообщений Windows.
DDE дает возможность перейти через рамки приложения и взаимодействовать с другими приложениями и системами Windows.
Dynamic Data Exchange получило свое имя потому, что позволяет двум приложениям обмениваться данными (текстовыми, через глобальную память) динамически во время выполнения. Связь между двумя программами можно установить таким образом, что изменения в одном приложении будут отражаться во втором. Например, если Вы меняете число в электронной таблице, то во втором приложении данные обновятся автоматически и отобразят изменения. Кроме того, с помощью DDE можно из своего приложения управлять другими приложениями такими, как Word for Windows, Report Smith, Excel и др.
Надеюсь, что данное краткое вступление поможет понять что предмет обсуждения представляет интерес. Далее рассказывается, как использовать компоненты Delphi для построения DDE приложений. Использование DDE
Приложение, получающее данные из другого приложения по DDE и/или управляющее другим приложением с помощью команд через DDE является DDE-клиентом. В этом случае второе приложение является DDE-сервером. Одно и то-же приложение может быть одновременно и сервером, и клиентом (например, MicroSoft Word). Построение DDE-серверов и DDE-клиентов удобно рассмотреть на примере, поставляемом с Delphi (каталог x:\delphi\demos\ddedemo). Сперва давайте рассмотрим логику работы примера. Для начала нужно откомпилировать проекты DDESRVR.DPR и DDECLI.DPR, после этого запустите программу DDECLI.EXE (DDE-клиент) и выберите пункт меню File|New Link.
При этом должна запуститься программа DDESRVR (DDE-сервер). Если теперь редактировать текст в окне сервера, то изменения мгновенно отразятся в приложении-клиенте (см. рис.1, рис.2)

Рис.1: Приложение - DDE-сервер. Здесь идет редактирование текста.

Рис.2: Приложение - DDE-клиент. Здесь отображаются изменения.
Пример демонстрирует и другие возможности DDE: - пересылка данных из клиента на сервер (Poke Data); наберите любой текст в правом окне DDE-клиента и нажмите кнопку Poke Data, этот текст появится в окне сервера. - исполнение команд (макросов) на сервере; наберите любой текст в правом окне DDE-клиента и нажмите кнопку Exec Macro, DDE-сервер выдаст соответствующее диалоговое окно. - установление связи через Clipboard; закройте оба DDE-приложения и запустите их заново, затем в DDE-сервере выберите пункт меню Edit|Copy, далее в клиенте выберите пункт меню Edit|Paste Link.
Теперь давайте рассмотрим эти демонстрационные программы с технической точки зрения и узнаем, каким образом в Delphi можно создать DDE-приложения. Начнем с DDE-сервера.
DDE-серверы
На рис.3 представлен пример DDE-сервера во время дизайна в среде Delphi.
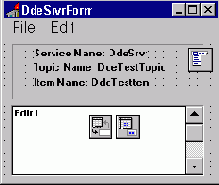
Рис.3: DDE-сервер в среде Delphi.
Для построении DDE-сервера в Delphi имеются два объекта, расположенные на странице System Палитры Компонент - TDdeServerConv и TDdeServerItem. Обычно в проекте используется один объект TDdeServerConv и один или более TDdeServerItem. Для получения доступа к сервису DDE-сервера, клиенту потребуется знать несколько параметров : имя сервиса (Service Name) - это имя приложения (обычно - имя выполняемого файла без расширения EXE, возможно с полным путем); Topic Name - в Delphi это имя компоненты TDdeServerConv; Item Name - в Delphi это имя нужной компоненты TDdeServerItem.
Назначение объекта TDdeServerConv - общее управление DDE и обработка запросов от клиентов на выполнение макроса. Последнее выполняется в обработчике события OnExecuteMacro, например, как это сделано в нашем случае:
procedure TDdeSrvrForm.doMacro(Sender: TObject;
Msg: TStrings);
var
Text: string;
begin
Text := '';
if Msg.Count > 0 then Text := Msg.Strings[0];
MessageDlg ('Executing Macro - ' + Text, mtInformation,
[mbOK], 0);
end;
Объект TDdeServerItem связывается с TDdeServerConv и определяет, что, собственно, будет пересылаться по DDE. Для этого у него есть свойства Text и Lines. (Text имеет то же значение, что и Lines[0].) При изменении значения этих свойств автоматически происходит пересылка обновленных данных во все приложения-клиенты, установившие связь с сервером. В нашем приложении изменение значения свойства Lines происходит в обработчике события OnChange компонента Edit1:
procedure TDdeSrvrForm.doOnChange(Sender: TObject);
begin
if not FInPoke then
DdeTestItem.Lines := Edit1.Lines;
end;
Этот же компонент отвечает за получение данных от клиента, в нашем примере это происходило при нажатии кнопки Poke Data, это выполняется в обработчике события OnPokeData:
procedure TDdeSrvrForm.doOnPoke(Sender: TObject);
begin
FInPoke := True;
Edit1.Lines := DdeTestItem.Lines;
FInPoke := False;
end;
И последнее - установление связи через Clipboard. Для этого служит метод CopyToClipboard объекта TDdeServerItem. Необходимая информации помещается в Clipboard и может быть вызвана из приложения-клиента при установлении связи. Обычно, в DDE-серверах для этого есть специальный пункт меню Paste Special или Paste Link.
Итак, мы рассмотрели пример полнофункционального DDE-сервера, построенного с помощью компонент Delphi. Очень часто существующие DDE-серверы не полностью реализуют возможности DDE и предоставляют только часть сервиса. Например, ReportSmith позволяет по DDE только выполнять команды (макросы).
DDE-клиенты
На рис.4 представлен пример DDE-клиента во время дизайна в среде Delphi.
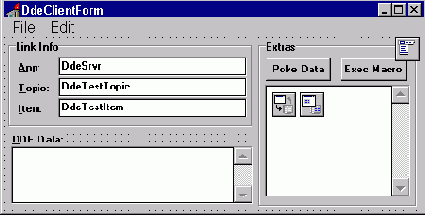
Рис.4: DDE-клиент в среде Delphi.
Для построения DDE-клиента в Delphi используются два компонента TDDEClientConv и TDDEClientItem. Аналогично серверу, в программе обычно используется один объект TDDEClientConv и один и более связанных с ним TDDEClientItem.
TDDEClientConv служит для установления связи с сервером и общим управлением DDE-связью. Установить связь с DDE-сервером можно как во время дизайна, так и во время выполнения программы, причем двумя способами. Первый способ - заполнить вручную необходимые свойства компонента. Это DdeService, DdeTopic и ServiceApplication. Во время дизайна щелкните дважды на одно из первых двух свойств в Инспекторе Объектов - Вы получите диалог для определения DDE-связи (см. рис.5).

Рис.5: Диалог для установления связи с DDE-сервером (Report Smith).
Укажите в диалоге имена DDE Service и DDE Topic. Эти имена можно узнать из документации по тому DDE-серверу, с которым Вы работаете. В случае DDE-сервера, созданного на Delphi, это имя программы (без .EXE) и имя объекта TDdeServerConv. Для установления связи через Clipboard в диалоге есть специальная кнопка Past Link. Ей можно воспользоваться, если Вы запустили DDE-сервер, сохранили каким-то образом информацию о связи и вошли в этот диалог. Например, если DDE-сервером является DataBase Desktop, то нужно загрузить в него какую-нибудь таблицу Paradox, выбрать любое поле и выбрать пункт меню Edit|Copy. После этого войдите в диалог и нажмите кнопку Paste Link. Поля в диалоге заполнятся соответствующим образом.
Свойство ServiceApplication заполняется в том случае, если в поле DDEService содержится имя, отличное от имени программы, либо если эта программа не находится в текущей директории. В этом поле указывается полный путь и имя программы без расширения (.EXE). При работе с Report Smith здесь нужно указать, например : C:\RPTSMITH\RPTSMITH
Данная информация нужна для автоматического запуска сервера при установлении связи по DDE, если тот еще не был запущен.
В нашей демо-программе связь устанавливается во время выполнения программы в пунктах меню File|New Link и Edit|Paste Link. В пункте меню File|New Link программно устанавливается связь по DDE с помощью соответствующего метода объекта TDdeServerConv, OpenLink делать не надо, поскольку свойство ConnectMode имеет значение ddeAutomatic:
procedure TFormD.doNewLink(Sender: TObject);
begin
DdeClient.SetLink(AppName.Text, TopicName.Text);
DdeClientItem.DdeConv := DdeClient;
DdeClientItem.DdeItem := ItemName.Text;
end;
Здесь же заполняются свойства объекта TDdeClietItem.
В пункте меню Edit|Past Link программно устанавливается связь по DDE с использованием информации из Clipboard:
procedure TFormD.doPasteLink(Sender: TObject);
var
Service, Topic, Item : String;
begin
if GetPasteLinkInfo (Service, Topic, Item) then
begin
AppName.Text := Service;
TopicName.Text := Topic;
ItemName.Text := Item;
DdeClient.SetLink (Service, Topic);
DdeClientItem.DdeConv := DdeClient;
DdeClientItem.DdeItem := ItemName.Text;
end;
end;
После того, как установлена связь, нужно позаботиться о поступающих по DDE данных, это делается в обработчике события OnChange объекта TDdeClietItem:
procedure TFormD.DdeClientItemChange(Sender: TObject);
begin
DdeDat.Lines := DdeClientItem.Lines;
end;
Это единственная задача объекта TDdeClientItem.
На объект TDdeClientConv возлагаются еще две задачи : пересылка данных на сервер и выполнение макросов. Для этого у данного объекта есть соответствующие методы. Посмотрим, как это можно было бы сделать. Выполнение макроса на сервере:
procedure TFormD.doMacro(Sender: TObject);
begin
DdeClient.ExecuteMacroLines(XEdit.Lines, True);
end;
Пересылка данных на сервер:
procedure TFormD.doPoke (Sender: TObject);
begin
DdeClient.PokeDataLines(DdeClientItem.DdeItem,XEdit.Lines);
end;
Управление ReportSmith по DDE В прилагаемом примере run-time версия ReportSmith выполняет команду, переданную по DDE. Имена DDE сервиса для ReportSmith и некоторых других приложений можно узнать в Справочнике в среде ReportSmith.
Перед запуском примера нужно правильно установить в свойстве ServiceApplication путь к run-time версии ReportSmith и в тексте программы в строке
Cmd:='LoadReport "c:\d\r\video\summary.rpt","@Repvar1=<40>,@Repvar2=<'#39'Smith'#39'>"'#0;
правильно указать путь к отчету.
Из статьи Вы узнаете основные

Содержание урока 13:
Обзор
Основы OLE
Объект TOLEContainer
Пример OLE приложения
Сохранение OLE объекта в базе данных
Обзор
Из статьи Вы узнаете основные сведения об OLE, некоторые вещи относительно OLE 2 и OLE Automation. В статье рассказывается об использовании объекта TOLEContainer для построения OLE приложения в Delphi. Основы OLE
Прежде, чем перейти к рассмотрению основ OLE, потребуется изучить терминологию.
Аббревиатура OLE обозначает Objects Linked and Embedded (Присоединенные И Встроенные Объекты - ПИВО J ). Данные, разделяемые между приложениями называются OLE объектом. Приложение, которое может содержать OLE объекты, называют OLE контейнером (OLE Container). Приложение, данные из которого можно включить в OLE контейнер в виде OLE объекта, называют OLE сервером.
Например, MicroSoft Word может включать в документ графические объекты, аудио- и видеоклипы и множество других объектов (такой документ иногда называют составным документом - compound document ).
Как следует из названия, OLE объекты можно либо присоединить к OLE контейнеру, либо включить в него. В первом случае данные будут храниться в файле на диске, любое приложение будет иметь доступ к этим данным и сможет вносить изменения. Во втором случае данные включаются в OLE контейнер и только он сможет просматривать и модифицировать эти данные.
OLE является дальнейшим развитием идеи разделяемых между приложениями данных. Если с помощью DDE можно было работать с текстом, то OLE позволяет легко встроить в приложение обработку любых типов данных. Как и в случае с DDE, для правильной работы приложения-клиента (OLE контейнера) требуется наличие приложения OLE сервера. Каждый раз, когда в программе-клиенте пользователь обращается к OLE объекту с целью просмотра или редактирования данных (обычно двойной щелчок мышкой на объекте), запускается приложение-сервер, в котором и происходит работа с данными.
В природе существует несколько видов OLE, отличающихся по способу активации OLE сервера. OLE версии 1 запускает сервер в отдельном окне. OLE 2 реализует то, что называется in-place activation and editing. В данном случае сервер запускается “внутри” приложения-клиента, модифицирует вид системного меню, линейки инструментов и др. Развитие идеи OLE привело к появлению OLE automation - приложение-клиент может выполнить часть кода сервера. Тип OLE объекта, помещенного в программу-клиент, определяется тем, какую версию OLE
поддерживает сервер. Объект TOLEContainer
Объект TOLEContainer находится на странице System Палитры Компонент и нужен для создания приложений OLE-контейнеров. TOLEContainer скрывает все сложности, связанные с внутренней организацией OLE и предоставляет программисту достаточно простой интерфейс. Построим простейшее приложение с использованием OLE объекта. Создайте новый проект и поместите на форму TOLEContainer, в Инспекторе Объектов дважды щелкните мышкой на свойство ObjClass или ObjDoc - появится стандартный диалог Windows “Insert Object” (см. рис.1)

В этом диалоге есть список всех зарегистрированных в системе OLE-серверов (регистрация происходит при инсталляции программы). Тип OLE-объекта определяется как раз тем сервером, который Вы укажете. Если Вы создаете новый объект (Create New), то при нажатии кнопки OK запустится программа OLE-сервер, в которой и формируется новый объект. После выхода из программы-сервера новый OLE объект включается (embedded object) в программу. OLE объект можно создать используя уже имеющийся файл в формате одного из OLE-серверов. Для этого нужно выбрать пункт Create from File (см. рис.2)

Выбранный объект можно как включить в приложение, так и присоединить, отметив пункт Link.
Итак, давайте при создании нашего проекта создадим новый объект, выбрав для этого, например, Microsoft Word Document (рис.1). Нажмите OK и после того, как запустится MS Word, наберите там любой текст (“Это OLE-объект Microsoft Word document”). Для завершения работы в меню есть специальный пункт “File|Close and Return to Form1” (Win’95+MS Word 7.0). Запустите проект, он будет выглядеть примерно так:

Щелкните дважды мышкой на OLE-контейнер - запустится MS Word с документом из OLE-объекта, который можно редактировать, при этом все изменения сохраняются в OLE-объекте.
!!! Если во время дизайна Вы выбираете объект для включения в OLE-контейнер, то он полностью записывается в файл формы (FORM1.DFM) и в дальнейшем прикомпилируется к EXE файлу. В случае очень больших объектов это может привести во время дизайна к длительным паузам и даже к возникновению ошибки “Out of resource”. Поэтому рекомендуется большие объекты делать присоединенными (linked).
TOLEContainer позволяет отображать в программе объект в его непосредственном виде ( с различной степенью увеличения или уменьшения - свойство Zoom) или в виде пиктограммы, определяемой в диалоге на рис.1 (Display as Icon).
Выбор OLE-объекта может происходить не только во время дизайна, но и во время выполнения программы (об этом чуть ниже). Результаты работы с этим объектом можно сохранить в виде файла и в следующий раз восстановить его оттуда, для этого TOLEContainer имеет два метода SaveToFile и LoadFromFile.
Пример OLE приложения
Среди демонстрационных примеров, входящих в Delphi есть два, относящихся к работе с OLE-объектами (в директориях X:\DELPHI\DEMOS\OLE2 и X:\DELPHI\DEMOS\DOC\OLE2). Более полным является второй, который, кроме всего прочего является примером построения MDI приложения. Данная программа демонстрирует все основные возможности TOLEContainer и позволяет:
- создавать новый OLE контейнер во время выполнения программы;
- инициализировать OLE объект либо в стандартном диалоге Windows “Insert Object”, либо с помощью Clipboard, либо с помощью техники “перенести и бросить” (drag-and-drop);
- сохранить OLE объект в файле и восстановить его оттуда;

На рис.4 показан пример MDI приложения, содержащий два дочерних окна с OLE объектами. Для создания нового OLE объекта нужно выбрать пункт меню File|New и далее Edit|Insert Object. Появится стандартный диалог Windows для инициализации OLE объекта (см. рис.1). Если приложение OLE-сервер имеет возможность сохранять информацию об OLE объекте в Clipboard, то проинициализировать объект можно с помощью пункта меню Edit|Paste Special.
Достаточно интересной является возможность применения техники drag-and-drop в применении к OLE объектам. Запустите MS Word (разместите его окно так, чтобы было видно и OLE приложение), наберите какой-нибудь текст, выделите его и с помощью мышки перетащите и бросьте на главное MDI окно приложения. Появится новое дочернее окно с OLE контейнером, содержащим этот текст. Программирование данной возможности достаточно сложно. Полное описание технологии построения данного OLE приложения есть в документации в коробке с Delphi (User’s guide), этому посвящена отдельная глава. Сохранение OLE объекта в базе данных Иногда необходимо хранить OLE объекты не в файлах, а в базе данных (BLOB поле в таблице). Конечно, в данном случае OLE объект должен быть присоединенным (embedded) в целях переносимости. К сожалению, в стандартной поставке Delphi нет специального объекта типа TDBOLEContainer для данных целей, но OLE объект можно сохранять и восстанавливать с помощью методов SaveToStream и LoadFromStream. Например:
procedure TOLEForm.SaveOLE(Sender: TObject);
var
BlSt : TBlobStream;
begin
With Table1 do
BlSt:=TBlobStream.Create(BlobField(FieldByName('OLE')),
bmReadWrite);
OLEContainer.SaveToStream(BlSt as TStream);
BlSt.Free;
end;
использующие объекты VCL для работы

Содержание урока 14:
Понятие DLL
Создание DLL в Delphi (экспорт)
Использование DLL в Delphi (импорт)
DLL, использующие объекты VCL для работы с данными
Исключительные ситуации в DLL При подготовке первой части данного материала использовался 13 выпуск Библиотеки Системного Программиста , Диалог-МИФИ 1994 г. Авторы: А.В.Фролов и Г.В.Фролов
Понятие DLL
Вспомним процесс программирования в DOS. Преобразование исходного текста программы в машинный код включал в себя два процесса - компиляцию и линковку. В процессе линковки, редактор связей, компоновавший отдельные модули программы, помещал в код программы не только объявления функций и процедур, но и их полный код. Вы готовили таким образом одну программу, другую, третью ... И везде код одних и тех же функций помещался в программу полностью (см. рис 1).
Рис.1 : Вызов функций при использовании статической компоновки
В многозадачной среде такой подход был бы по меньшей мере безрассудным, так как очевидно, что огромное количество одних и тех же функций, отвечающих за прорисовку элементов пользовательского интерфейса, за доступ к системным ресурсам и т.п. дублировались бы полностью во всех приложениях, что привело бы к быстрому истощению самого дорогого ресурса - оперативной памяти. В качестве решения возникшей проблемы, еще на UNIX-подобных платформах была предложена концепция динамической компоновки (см. рис . 2).
Рис.2: Вызов функций при использовании динамической компоновки
Но, чем же отличаются Dynamic Link Library (DLL) от обычных приложений? Для понимания этого требуется уточнить понятия задачи (task), экземпляра (копии) приложения (instance) и модуля (module).
При запуске нескольких экземпляров одного приложения, Windows загружает в оперативную память только одну копию кода и ресурсов - модуль приложения, создавая несколько отдельных сегментов данных, стека и очереди сообщений (см. рис. 3), каждый набор которых представляет из себя задачу, в понимании Windows. Копия приложения представляет из себя контекст, в котором выполняется модуль приложения.
Задача 1 Задача 2
Копия 1 приложения Копия 2 приложения
Данные Данные
Стек Стек
Очередь сообщений Очередь сообщений
Модуль приложения
Код
Ресурсы
Рис.3 : Копии приложения и модуль приложения
DLL - библиотека также является модулем. Она находится в памяти в единственном экземпляре и содержит сегмент кода и ресурсы, а также сегмент данных (см. рис. 4).
DLL-библиотека
Код
Ресурсы
Данные
Рис.4 : Структура DLL в памяти
DLL - библиотека, в отличие от приложения не имеет ни стека, ни очереди сообщений. Функции, помещенные в DLL, выполняются в контексте вызвавшего приложения, пользуясь его стеком. Но эти же функции используют сегмент данных, принадлежащий библиотеке, а не копии приложения.
В силу такой организации DLL, экономия памяти достигается за счет того, что все запущенные приложения используют один модуль DLL, не включая те или иные стандартные функции в состав своих модулей.
Часто, в виде DLL создаются отдельные наборы функций, объединенные по тем или иным логическим признакам, аналогично тому, как концептуально происходит планирование модулей ( в смысле unit ) в Pascal. Отличие заключается в том, что функции из модулей Pascal компонуются статически - на этапе линковки, а функции из DLL компонуются динамически, то есть в run-time.
Создание DLL в Delphi (экспорт) Для программирования DLL Delphi предоставляет ряд ключевых слов и правил синтаксиса. Главное - DLL в Delphi такой же проект как и программа.
Рассмотрим шаблон DLL:
library MyDll;
uses
<используемые модули>;
<объявления и описания функций>
exports
<экспортируемые функции>
begin
<инициализационная часть>
end.
Имя файла проекта для такого шаблона должно быть MYDLL.DPR.
!!!! К сожалению, в IDE Delphi автоматически генерируется только проект программы, поэтому Вам придется проект DLL готовить вручную. В Delphi 2.0 это неудобство устранено.
Как и в программе, в DLL присутствует раздел uses. Инициализационная часть необязательна. В разделе же exports перечисляются функции, доступ к которым должен производится из внешних приложений.
Экспортирование функций (и процедур ) может производится несколькими способами: по номеру (индексу); по имени. В зависимости от этого используется различный синтаксис:
{экспорт по индексу}
procedure ExportByOrdinal; export;
begin
.....
end;
exports
ExportByOrdinal index 10;
{экспорт по имени}
procedure ExportByName; export;
begin
.....
end;
exports
ExportByName name 'MYEXPORTPROC'; { имя для экспорта может не совпадать с именем функции ! }
Так как в Windows существует понятие "резидентных функций" DLL, то есть тех функций, которые находятся в памяти на протяжении всего времени существования DLL в памяти, в Delphi имеются средства для организации и такого рода экспорта:
exports
ExportByName name 'MYEXPORTPROC' resident;
Стоит отметить тот факт, что поиск функций, экспортируемых по индексу, производится быстрее, чем при экспорте по имени. С другой стороны, экспорт по имени удобнее, особенно если Вы периодически дополняете и расширяете набор экспортируемых из DLL функций, при гарантии работы приложений, использующих DLL, и не хотите специально следить за соблюдением уникальности и соответствия индексов.
Если же Вы будете экспортировать функции следующим образом:
exports
MyExportFunc1,
MyExportFunc2,
.....;
то индексирование экспортируемых функций будет произведено Delphi автоматически, а такой экспорт будет считаться экспортом по имени, совпадающему с именем функции. Тогда объявление импортируемой функции в приложении должно совпадать по имени с объявлением функции в DLL. Что же касается директив, накладываемых уже на импортируемые функции, то об этом мы поговорим ниже.
Использование DLL в Delphi (импорт)
Для организации импорта, т.е. доступа к функциям, экспортируемым из DLL, так же как и для их экспорта, Delphi предоставляет стандартные средства.
Для показанных выше примеров, в Вашей программе следует объявить функции, импортируемые из DLL таким образом:
{ импорт по специфицированному имени }
procedure ImportByName;external 'MYDLL' name 'MYEXPORTPROC';
{ импорт по индексу }
procedure ImportByOrdinal; external 'MYDLL' index 10;
{ импорт по оригинальному имени }
procedure MyExportFunc1; external 'MYDLL';
Этот способ называется статическим импортом.
Как Вы могли заметить, расширение файла, содержащего DLL, не указывается - по умолчанию подразумеваются файлы *.DLL и *.EXE. Как же тогда быть в случае, если файл имеет другое расширение (например, как COMPLIB.DCL в Delphi), или если требуется динамическое определение DLL и импортируемых функций (например, Ваша программа работает с различными графическими форматами, и для каждого из них существует отдельная DLL.)?
Для решения такого рода проблем Вы можете обратиться напрямую к API Windows, используя, так называемый, динамический импорт:
uses
WinTypes, WinProcs, ... ;
type
TMyProc = procedure ;
var
Handle : THandle;
MyImportProc : TMyProc;
begin
Handle:=LoadLibrary('MYDLL');
if Handle>=32 then { if <=32 - error ! }
begin
@MyImportProc:=GetProcAddress(Handle,'MYEXPORTPROC');
if MyImportProc<>nil then
...... {using imported procedure}
end;
FreeLibrary(Handle);
end;
!!! Синтаксические диаграммы объявлений экспорта/импорта, подмена точки выхода из DLL, и другие примеры, Вы можете найти в OnLine Help Delphi, Object Pascal Language Guide, входящему в Borland RAD Pack for Delphi, и, например, в книге "Teach Yourself Delphi in 21 Days".
Если не говорить о генерируемом компилятором коде (сейчас он более оптимизирован), то все правила синтаксиса остались те же , что и в Borland Pascal 7.0
DLL, использующие объекты VCL для работы с данными
При создании своей динамической библиотеки Вы можете использовать вызовы функций из других DLL. Пример такой DLL есть в поставке Delphi (X:\DELPHI\DEMOS\BD\BDEDLL). В эту DLL помещена форма, отображающая данные из таблицы и использующая для доступа к ней объекты VCL (TTable, TDBGrid, TSession), которые, в свою очередь, вызывают функции BDE. Как следует из комментариев к этому примеру, для такой DLL имеется ограничение: ее не могут одновременно использовать несколько задач. Это вызвано тем, что объект Session, который создается автоматически при подключении модуля DB, инициализируется для модуля, а не для задачи. Если попытаться загрузить эту DLL вторично из другого приложения, то возникнет ошибка. Для предотвращения одновременной загрузки DLL несколькими задачами нужно осуществить некоторые действия. В примере - это процедура проверки того, используется ли DLL в данный момент другой задачей. Исключительные ситуации в DLL Возникновение исключительной ситуации в DLL, созданной в Delphi, приведет к прекращению выполнения всего приложения, если эта ситуация не была обработана внутри DLL. Поэтому желательно предусмотреть все возможные неприятности на момент разработки DLL. Можно порекомендовать возвращать результат выполнения импортируемой функции в виде строки или числа и, при необходимости, заново вызывать исключительную ситуацию в программе.
Код в DLL:
function MyFunc : string;
begin
try
{собственно код функции}
except
on EResult: Exception do
Result:=Format(DllErrorViewingTable, [EResult.Message]); else
Result := Format(DllErrorViewingTable, ['Unknown error']); end;
end;
Код в программе:
StrResult:=MyFunc;
if StrResult<>’’ then
raise Exception.Create(StrResult);
В этом уроке описываются основы
32 урока по Delphi

Содержание урока 15:
Обзор
Требования к базам данных
Основные концепции реляционных баз данных
Шаги проектирования базы данных
Приведение к первой нормальной форме
Приведение ко второй нормальной форме
Приведение к третьей нормальной форме
Заключение
Обзор
В этом уроке описываются основы работы с базами данных. Напомним, что под базой данных понимается некоторая унифицированная совокупность данных, совместно используемая персоналом/населением группы, предприятия, региона, страны, мира... Задача базы данных состоит в хранении всех представляющих интерес данных в одном или нескольких местах, причем таким способом, который заведомо исключает ненужную избыточность. В хорошо спроектированной базе данных избыточность данных исключается, и вероятность сохранения противоречивых данных минимизируется. Таким образом, создание баз данных преследует две основные цели: понизить избыточность данных и повысить их надежность.
Во вводном уроке (номер 1) мы дали краткое, “на пальцах”, толкование локальных и серверных баз данных и пояснили суть технологии клиент-сервер. На данном уроке мы рассмотрим процесс проектирования баз данных, общий для обеих технологий. И лишь детали его реализации будут различаться в разных архитектурах. Сразу оговоримся, что мы будем рассматривать только реляционные базы данных: во-первых, реляционные базы получили наибольшее распространение в мире; во-вторых, они наиболее “продвинуты” в научном плане; а в-третьих, ядро баз данных Borland Database Engine, на основе которого работают все последние продукты компании Borland, предназначено именно для работы с реляционными базами данных.
Жизненный цикл любого программного продукта, в том числе и системы управления базой данных, состоит (по-крупному) из стадий проектирования, реализации и эксплуатации.
Естественно, наиболее значительным фактором в жизненном цикле приложения, работающего с базой данных, является стадия проектирования. От того, насколько тщательно продумана структура базы, насколько четко определены связи между ее элементами, зависит производительность системы и ее информационная насыщенность, а значит - и время ее жизни.
Требования к базам данных Итак, хорошо спроектированная база данных: Удовлетворяет всем требованиям пользователей к содержимому базы данных. Перед проектированием базы необходимо провести обширные исследования требований пользователей к функционированию базы данных. Гарантирует непротиворечивость и целостность данных. При проектировании таблиц нужно определить их атрибуты и некоторые правила, ограничивающие возможность ввода пользователем неверных значений. Для верификации данных перед непосредственной записью их в таблицу база данных должна осуществлять вызов правил модели данных и тем самым гарантировать сохранение целостности информации. Обеспечивает естественное, легкое для восприятия структурирование информации. Качественное построение базы позволяет делать запросы к базе более “прозрачными” и легкими для понимания; следовательно, снижается вероятность внесения некорректных данных и улучшается качество сопровождения базы. Удовлетворяет требованиям пользователей к производительности базы данных. При больших объемах информации вопросы сохранения производительности начинают играть главную роль, сразу “высвечивая” все недочеты этапа проектирования. Следующие пункты представляют основные шаги проектирования базы данных: Определить информационные потребности базы данных. Проанализировать объекты реального мира, которые необходимо смоделировать в базе данных. Сформировать из этих объектов сущности и характеристики этих сущностей (например, для сущности “деталь” характеристиками могут быть “название”, “цвет”, “вес” и т.п.) и сформировать их список. Поставить в соответствие сущностям и характеристикам - таблицы и столбцы (поля) в нотации выбранной Вами СУБД (Paradox, dBase, FoxPro, Access, Clipper, InterBase, Sybase, Informix, Oracle и т.д.). Определить атрибуты, которые уникальным образом идентифицируют каждый объект. Выработать правила, которые будут устанавливать и поддерживать целостность данных. Установить связи между объектами (таблицами и столбцами), провести нормализацию таблиц.
Спланировать вопросы надежности данных и, при необходимости, сохранения секретности информации. Основные концепции реляционных баз данных Прежде чем подробно рассматривать каждый из этих шагов, остановимся на основных концепциях реляционных баз данных. В реляционной теории одним из главных является понятие отношения. Математически отношение определяется следующим образом. Пусть даны n множеств D1,D2,...,Dn. Тогда R есть отношение над этими множествами, если R есть множество упорядоченных наборов вида <d1,d2,...,dn>, где d1 - элемент из D1, d2 - элемент из D2, ..., dn - элемент из Dn. При этом наборы вида <d1,d2,...,dn> называются кортежами, а множества D1,D2,...,Dn - доменами. Каждый кортеж состоит из элементов, выбираемых из своих доменов. Эти элементы называются атрибутами, а их значения - значениями атрибутов. рис. ошибка! текст указанного стиля в документе отсутствует.-a представляет нам графическое изображение отношения с разных точек зрения.

Атрибут (или набор атрибутов), который может быть использован для однозначной идентификации конкретного кортежа (строки, записи), называется первичным ключом. Первичный ключ не должен иметь дополнительных атрибутов. Это значит, что если из первичного ключа исключить произвольный атрибут, оставшихся атрибутов будет недостаточно для однозначной идентификации отдельных кортежей. Для ускорения доступа по первичному ключу во всех системах управления базами данных (СУБД) имеется механизм, называемый индексированием. Грубо говоря, индекс представляет собой инвертированный древовидный список, указывающий на истинное местоположение записи для каждого первичного ключа. Естественно, в разных СУБД индексы реализованы по-разному (в локальных СУБД - как правило, в виде отдельных файлов), однако, принципы их организации одинаковы.
Возможно индексирование отношения с использованием атрибутов, отличных от первичного ключа. Данный тип индекса называется вторичным индексом и применяется в целях уменьшения времени доступа при нахождении данных в отношении, а также для сортировки. Таким образом, если само отношение не упорядочено каким-либо образом и в нем могут присутствовать строки, оставшиеся после удаления некоторых кортежей, то индекс (для локальных СУБД - индексный файл), напротив, отсортирован.
Для поддержания ссылочной целостности данных во многих СУБД имеется механизм так называемых внешних ключей. Смысл этого механизма состоит в том, что некоему атрибуту (или группе атрибутов) одного отношения назначается ссылка на первичный ключ другого отношения; тем самым закрепляются связи подчиненности между этими отношениями. При этом отношение, на первичный ключ которого ссылается внешний ключ другого отношения, называется master-отношением, или главным отношением; а отношение, от которого исходит ссылка, называется detail-отношением, или подчиненным отношением. После назначения такой ссылки СУБД имеет возможность автоматически отслеживать вопросы “ненарушения“ связей между отношениями, а именно: если Вы попытаетесь вставить в подчиненную таблицу запись, для внешнего ключа которой не существует соответствия в главной таблице (например, там нет еще записи с таким первичным ключом), СУБД сгенерирует ошибку; если Вы попытаетесь удалить из главной таблицы запись, на первичный ключ которой имеется хотя бы одна ссылка из подчиненной таблицы, СУБД также сгенерирует ошибку. если Вы попытаетесь изменить первичный ключ записи главной таблицы, на которую имеется хотя бы одна ссылка из подчиненной таблицы, СУБД также сгенерирует ошибку. Замечание. Существует два подхода к удалению и изменению записей из главной таблицы: Запретить удаление всех записей, а также изменение первичных ключей главной таблицы, на которые имеются ссылки подчиненной таблицы. Распространить всякие изменения в первичном ключе главной таблицы на подчиненную таблицу, а именно:
если в главной таблице удалена запись, то в подчиненной таблице должны быть удалены все записи, ссылающиеся на удаляемую; если в главной таблице изменен первичный ключ записи, то в подчиненной таблице должны быть изменены все внешние ключи записей, ссылающихся на изменяемую. Итак, после того как мы ознакомились с основными понятиями реляционной теории, можно перейти к детальному рассмотрению шагов проектирования базы данных, которые мы перечислили на стр. *.
Шаги проектирования базы данных I. Первый шаг состоит в определении информационных потребностей базы данных. Он включает в себя опрос будущих пользователей для того, чтобы понять и задокументировать их требования. Следует выяснить следующие вопросы: сможет ли новая система объединить существующие приложения или их необходимо будет кардинально переделывать для совместной работы с новой системой; какие данные используются разными приложениями; смогут ли Ваши приложения совместно использовать какие-либо из этих данных; кто будет вводить данные в базу и в какой форме; как часто будут изменяться данные; достаточно ли будет для Вашей предметной области одной базы или Вам потребуется несколько баз данных с различными структурами; какая информация является наиболее чувствительной к скорости ее извлечения и изменения. II. Следующий шаг включает в себя анализ объектов реального мира, которые необходимо смоделировать в базе данных. Формирование концептуальной модели базы данных включает в себя: идентификацию функциональной деятельности Вашей предметной области. Например, если речь идет о деятельности предприятия, то в качестве функциональной деятельности можно идентифицировать ведение учета работающих, отгрузку продукции, оформление заказов и т.п. идентификацию объектов, которые осуществляют эту функциональную деятельность, и формирование из их операций последовательности событий, которые помогут Вам идентифицировать все сущности и взаимосвязи между ними. Например, процесс “ведение учета работающих” идентифицирует такие сущности как РАБОТНИК, ПРОФЕССИЯ, ОТДЕЛ.
идентификацию характеристик этих сущностей. Например, сущность РАБОТНИК может включать такие характеристики как Идентификатор Работника, Фамилия, Имя, Отчество, Профессия, Зарплата. идентификацию взаимосвязей между сущностями. Например, каким образом сущности РАБОТНИК, ПРОФЕССИЯ, ОТДЕЛ взаимодействуют друг с другом? Работник имеет одну профессию (для простоты!) и значится в одном отделе, в то время как в одном отделе может находиться много работников. III. Третий шаг заключается в установлении соответствия между сущностями и характеристиками предметной области и отношениями и атрибутами в нотации выбранной СУБД. Поскольку каждая сущность реального мира обладает некими характеристиками, в совокупности образующими полную картину ее проявления, можно поставить им в соответствие набор отношений (таблиц) и их атрибутов (полей). Перечислив все отношения и их атрибуты, уже на этом этапе можно начать устранять излишние позиции. Каждый атрибут должен появляться только один раз; и Вы должны решить, какое отношение будет являться владельцем какого набора атрибутов.
IV. На четвертом шаге определяются атрибуты, которые уникальным образом идентифицируют каждый объект. Это необходимо для того, чтобы система могла получить любую единичную строку таблицы. Вы должны определить первичный ключ для каждого из отношений. Если нет возможности идентифицировать кортеж с помощью одного атрибута, то первичный ключ нужно сделать составным - из нескольких атрибутов. Хорошим примером может быть первичный ключ в таблице работников, состоящий из фамилии, имени и отчества. Первичный ключ гарантирует, что в таблице не будет содержаться двух одинаковых строк. Во многих СУБД имеется возможность помимо первичного определять еще ряд уникальных ключей. Отличие уникального ключа от первичного состоит в том, что уникальный ключ не является главным идентифицирующим фактором записи и на него не может ссылаться внешний ключ другой таблицы. Его главная задача - гарантировать уникальность значения поля.
V. Пятый шаг предполагает выработку правил, которые будут устанавливать и поддерживать целостность данных. Будучи определенными, такие правила в клиент-серверных СУБД поддерживаются автоматически - сервером баз данных; в локальных же СУБД их поддержание приходится возлагать на пользовательское приложение.
Эти правила включают: определение типа данных выбор набора символов, соответствующего данной стране создание полей, опирающихся на домены установка значений по умолчанию определение ограничений целостности определение проверочных условий. VI. На шестом шаге устанавливаются связи между объектами (таблицами и столбцами) и производится очень важная операция для исключения избыточности данных - нормализация таблиц.
Каждый из различных типов связей должен быть смоделирован в базе данных. Существует несколько типов связей: связь “один-к-одному” связь “один-ко-многим” связь “многие-ко-многим”. Связь “один-к-одному” представляет собой простейший вид связи данных, когда первичный ключ таблицы является в то же время внешним ключом, ссылающимся на первичный ключ другой таблицы. Такую связь бывает удобно устанавливать тогда, когда невыгодно держать разные по размеру (или по другим критериям) данные в одной таблице. Например, можно выделить данные с подробным описанием изделия в отдельную таблицу с установлением связи “один-к-одному” для того чтобы не занимать оперативную память, если эти данные используются сравнительно редко.
Связь “один-ко-многим” в большинстве случаев отражает реальную взаимосвязь сущностей в предметной области. Она реализуется уже описанной парой “внешний ключ-первичный ключ”, т.е. когда определен внешний ключ, ссылающийся на первичный ключ другой таблицы. Именно эта связь описывает широко распространенный механизм классификаторов. Имеется справочная таблица, содержащая названия, имена и т.п. и некие коды, причем, первичным ключом является код. В таблице, собирающей информацию - назовем ее информационной таблицей - определяется внешний ключ, ссылающийся на первичный ключ классификатора. После этого в нее заносится не название из классификатора, а код. Такая система становится устойчивой от изменения названия в классификаторах. Имеются способы быстрой “подмены” в отображаемой таблице кодов на их названия как на уровне сервера БД (для клиент-серверных СУБД), так и на уровне пользовательского приложения. Но об этом - в дальнейших уроках.
Связь “многие-ко-многим” в явном виде в реляционных базах данных не поддерживается. Однако имеется ряд способов косвенной реализации такой связи, которые с успехом возмещают ее отсутствие. Один из наиболее распространенных способов заключается во введении дополнительной таблицы, строки которой состоят из внешних ключей, ссылающихся на первичные ключи двух таблиц. Например, имеются две таблицы: КЛИЕНТ и ГРУППА_ИНТЕРЕСОВ. Один человек может быть включен в различные группы, в то время как группа может объединять различных людей. Для реализации такой связи “многие-ко-многим” вводится дополнительная таблица, назовем ее КЛИЕНТЫ_В_ГРУППЕ, строка которой будет иметь два внешних ключа: один будет ссылаться на первичный ключ в таблице КЛИЕНТ, а другой - на первичный ключ в таблице ГРУППА_ИНТЕРЕСОВ. Таким образом в таблицу КЛИЕНТЫ_В_ГРУППЕ можно записывать любое количество людей и любое количество групп.
Итак, после определения таблиц, полей, индексов и связей между таблицами следует посмотреть на проектируемую базу данных в целом и проанализировать ее, используя правила нормализации, с целью устранения логических ошибок. Важность нормализации состоит в том, что она позволяет разбить большие отношения, как правило, содержащие большую избыточность информации, на более мелкие логические единицы, группирующие только данные, объединенные “по природе”. Таким образом, идея нормализации заключается в следующем. Каждая таблица в реляционной базе данных удовлетворяет условию, в соответствии с которым в позиции на пересечении каждой строки и столбца таблицы всегда находится единственное значение, и никогда не может быть множества таких значений.
После применения правил нормализации логические группы данных располагаются не более чем в одной таблице. Это дает следующие преимущества: данные легко обновлять или удалять исключается возможность рассогласования копий данных уменьшается возможность введения некорректных данных. Процесс нормализации заключается в приведении таблиц в так называемые нормальные формы. Существует несколько видов нормальных форм: первая нормальная форма (1НФ), вторая нормальная форма (2НФ), третья нормальная форма (3НФ), нормальная форма Бойса-Кодда (НФБК), четвертая нормальная форма (4НФ), пятая нормальная форма (5НФ). С практической точки зрения, достаточно трех первых форм - следует учитывать время, необходимое системе для “соединения” таблиц при отображении их на экране. Поэтому мы ограничимся изучением процесса приведения отношений к первым трем формам.
Этот процесс включает: устранение повторяющихся групп (приведение к 1НФ) удаление частично зависимых атрибутов (приведение к 2НФ) удаление транзитивно зависимых атрибутов (приведение к 3НФ). Рассмотрим каждый из этих процессов подробней. Приведение к первой нормальной форме
Когда поле в данной записи содержит более одного значения для каждого вхождения первичного ключа, такие группы данных называются повторяющимися группами. 1НФ не допускает наличия таких многозначных полей. Рассмотрим пример базы данных предприятия, содержащей таблицу ОТДЕЛ со следующими значениями (атрибут, выделенный курсивом, является первичным ключом):
Табл. A: ОТДЕЛ
| Номер_отдела | Название | Руководитель | Бюджет | Расположение |
| 100 | продаж | 000 | 1000000 | Москва |
| 100 | продаж | 000 | 1000000 | Зеленоград |
| 600 | разработок | 120 | 1100000 | Тверь |
| 100 | продаж | 000 | 1000000 | Калуга |
Для приведения этой таблицы к 1НФ мы должны устранить атрибут (поле) Расположение из таблицы ОТДЕЛ и создать новую таблицу РАСПОЛОЖЕНИЕ_ОТДЕЛОВ, в которой определить первичный ключ, являющийся комбинацией номера отдела и его расположения (Номер_отдела+Расположение - см. табл. b). Теперь для каждого расположения отдела существуют различные строки; тем самым мы устранили повторяющиеся группы.
Табл. B: РАСПОЛОЖЕНИЕ_ОТДЕЛОВ
| Номер_отдела | Расположение |
| 100 | Москва |
| 100 | Зеленоград |
| 600 | Тверь |
| 100 | Калуга |
Приведение ко второй нормальной форме
Следующий важный шаг в процессе нормализации состоит в удалении всех неключевых атрибутов, которые зависят только от части первичного ключа. Такие атрибуты называются частично зависимыми. Неключевые атрибуты заключают в себе информацию о данной сущности предметной области, но не идентифицируют ее уникальным образом. Например, предположим, что мы хотим распределить работников по проектам, ведущимся на предприятии. Для этого создадим таблицу ПРОЕКТ с составным первичным ключом, включающим номер работника и идентификатор проекта (Номер_работника+ИД_проекта, в табл. c выделены курсивом).
Табл. C: ПРОЕКТ
| Номер_
работника |
ИД_проекта | Фамилия | Назв_проекта | Описание_
проекта |
Продукт |
| 28 | БРЖ | Иванов | Биржа | <blob> | программа |
| 17 | ДОК | Петров | Документы | <blob> | программа |
| 06 | УПР | Сидоров | Управление | <blob> | адм.меры |
В этой таблице возникает следующая проблема. Атрибуты Назв_проекта, Описание_проекта и Продукт относятся к проекту как сущности и, следовательно, зависят от атрибута ИД_проекта (являющегося частью первичного ключа), но не от атрибута Номер_работника. Следовательно, они являются частично зависимыми от составного первичного ключа. То же самое можно сказать и об атрибуте Фамилия, который зависит от атрибута Номер_работника, но не зависит от атрибута ИД_проекта. Для нормализации этой таблицы (приведения ее в 2НФ) удалим из нее атрибуты Номер_работника и Фамилия и создадим другую таблицу (назовем ее РАБОТНИК_В_ПРОЕКТЕ), которая будет содержать только эти два атрибута, и они же будут составлять ее первичный ключ. Приведение к третьей нормальной форме Третий этап процесса приведения таблиц к нормальной форме состоит в удалении всех неключевых атрибутов, которые зависят от других неключевых атрибутов. Каждый неключевой атрибут должен быть логически связан с атрибутом (атрибутами), являющимся первичным ключом. Предположим, например, что мы добавили поля Номер_руководителя и Телефон в таблицу ПРОЕКТ, находящуюся в 2НФ (первичным ключом является поле ИД_проекта). Атрибут Телефон логически связан с атрибутом Номер_руководителя, неключевым полем, но не с атрибутом ИД_проекта, являющимся первичным ключом (табл. d).
Табл. D: ПРОЕКТ
| ИД_проекта | Номер_
руководителя |
Телефон | Назв_
проекта |
Описание_
проекта |
Продукт |
| БРЖ | 02 | 2-21 | Биржа | <blob> | программа |
| ДОК | 12 | 2-43 | Документы | <blob> | программа |
| УПР | 08 | 2-56 | Управление | <blob> | адм.меры |
Для нормализации этой таблицы (приведения ее в 3НФ) удалим атрибут Телефон, изменим Номер_руководителя на Руководитель и сделаем атрибут Руководитель
внешним ключом, ссылающимся на атрибут Номер_работника (первичный ключ) в таблице РАБОТНИКИ. После этого таблицы ПРОЕКТ и РАБОТНИКИ будут выглядеть следующим образом: Табл. E: ПРОЕКТ
| ИД_проекта | Руководитель | Назв_
проекта |
Описание_
проекта |
Продукт |
| БРЖ | 02 | Биржа | <blob> | программа |
| ДОК | 12 | Документы | <blob> | программа |
| УПР | 08 | Управление | <blob> | адм.меры |
Табл. F: РАБОТНИКИ
| Номер_
работника |
Фамилия | Имя | Отчество | Номер_
отдела |
Код_
профес |
Телефон | Зарплата | |
| 04 | Иванов | Иван | Иванович | 100 | инж | 2-69 | 500 | |
| 08 | Петров | Петр | Петрович | 200 | мндж | 2-56 | 1000 | |
| 23 | Сидоров | Иван | Петрович | 200 | мндж | 2-45 | 800 | |
Теперь, когда мы научились проводить нормализацию таблиц с целью устранения избыточного дублирования данных и группирования информации в логически связанных единицах, необходимо сделать ряд замечаний по вопросам проектирования баз данных. Необходимо четко понимать, что разбиение информации на более мелкие единицы с одной стороны, способствует повышению надежности и непротиворечивости базы данных, а с другой стороны, снижает ее производительность, так как требуются дополнительные затраты процессорного времени (серверного или машины пользователя) на обратное “соединение” таблиц при представлении информации на экране. Иногда для достижения требуемой производительности нужно сделать отход от канонической нормализации, при этом ясно осознавая, что необходимо обеспечить меры по предотвращению противоречивости в данных. Поэтому всякое решение о необходимости того или иного действия по нормализации можно принимать только тщательно проанализировав предметную область и класс поставленной задачи. Может потребоваться несколько итераций для достижения состояния, которое будет желаемым компромиссом между четкостью представления и реальными возможностями техники. Здесь уже начинается искусство...
VII. Седьмой шаг является последним в нашем списке, но не последним по важности в процессе проектирования базы данных. На этом шаге мы должны спланировать вопросы надежности данных и, при необходимости, сохранения секретности информации. Для этого необходимо ответить на следующие вопросы: кто будет иметь права (и какие) на использование базы данных кто будет иметь права на модификацию, вставку и удаление данных нужно ли делать различие в правах доступа каким образом обеспечить общий режим защиты информации и т.п. Заключение На данном уроке мы познакомились с основами теории реляционных баз данных, изучили требования к базам данных, а также основные шаги по проектированию баз данных. Кроме того, рассмотрели очень важный для проектирования баз данных вопрос нормализации таблиц и проблемы, связанные с этим процессом. Теперь мы можем осознанно приступать к созданию приложений, работающих с базами данных.
Системная информация утилиты настройки BDE
32 урока по Delphi

Урок 16: Настройка BDE
Содержание урока 16:
Обзор
Сущность BDE
Алиасы
Системная информация утилиты настройки BDE (BDECFG)
Установка драйверов ODBC и других драйверов
Заключение Обзор
На этом уроке мы познакомимся с ядром баз данных компании Борланд - Borland Database Engine (BDE), а также научимся создавать и редактировать алиасы - механизм, облегчающий связь с базами данных. Кроме того, мы изучим, как конфигурировать ODBC драйверы.
Сущность BDE
Мощность и гибкость Delphi при работе с базами данных основана на низкоуровневом ядре - процессоре баз данных Borland Database Engine (BDE). Его интерфейс с прикладными программами называется Integrated Database Application Programming Interface (IDAPI). В принципе, сейчас не различают эти два названия (BDE и IDAPI) и считают их синонимами. BDE позволяет осуществлять доступ к данным как с использованием традиционного record-ориентированного (навигационного) подхода, так и с использованием set-ориентированного подхода, используемого в SQL-серверах баз данных. Кроме BDE, Delphi позволяет осуществлять доступ к базам данных, используя технологию (и, соответственно, драйверы) Open DataBase Connectivity (ODBC) фирмы Microsoft. Но, как показывает практика, производительность систем с использованием BDE гораздо выше, чем оных при использовании ODBC. ODBC драйвера работают через специальный “ODBC socket”, который позволяет встраивать их в BDE.
Все инструментальные средства баз данных Borland - Paradox, dBase, Database Desktop - используют BDE. Все особенности, имеющиеся в Paradox или dBase, “наследуются” BDE, и поэтому этими же особенностями обладает и Delphi.
Алиасы Таблицы сохраняются в базе данных. Некоторые СУБД сохраняют базу данных в виде нескольких отдельных файлов, представляющих собой таблицы (в основном, все локальные СУБД), в то время как другие состоят из одного файла, который содержит в себе все таблицы и индексы (InterBase). Например, таблицы dBase и Paradox всегда сохраняются в отдельных файлах на диске. Директорий, содержащий dBase .DBF файлы или Paradox .DB файлы, рассматривается как база данных. Другими словами, любой директорий, содержащий файлы в формате Paradox или dBase, рассматривается Delphi как единая база данных. Для переключения на другую базу данных нужно просто переключиться на другой директорий. Как уже было указано выше, InterBase сохраняет все таблицы в одном файле, имеющем расширение .GDB, поэтому этот файл и есть база данных InterBase.
Удобно не просто указывать путь доступа к таблицам базы данных, а использовать для этого некий заменитель - псевдоним, называемый алиасом. Он сохраняется в отдельном конфигурационном файле в произвольном месте на диске и позволяет исключить из программы прямое указание пути доступа к базе данных. Такой подход дает возможность располагать данные в любом месте, не перекомпилируя при этом программу. Кроме пути доступа, в алиасе указываются тип базы данных, языковый драйвер и много другой управляющей информации. Поэтому использование алиасов позволяет легко переходить от локальных баз данных к SQL-серверным базам (естественно, при выполнении требований разделения приложения на клиентскую и серверную части).
Для создания алиаса запустите утилиту конфигурации BDE (программу BDECFG.EXE), находящуюся в директории, в котором располагаются динамические библиотеки BDE.

Главное окно утилиты настройки BDE имеет вид, изображенный на рис.1. Для создания алиаса выберите страничку “Aliases” и нажмите кнопку “New Alias”. В появившемся диалоговом окне введите имя алиаса и выберите его тип (тип базы данных) из выпадающего списка. Тип алиаса может быть стандартным (STANDARD) для работы с локальными базами в формате dBase или Paradox или соответствовать наименованию SQL-сервера (InterBase, Sybase, Informix, Oracle и т.д.).


После создания нового алиаса его имя появится в списке алиасов на той же страничке “Aliases”. Однако просто создать алиас не достаточно. Вам нужно указать дополнительную информацию, содержание которой зависит от типа выбранной базы данных. Например, для баз данных Paradox и dBase (STANDARD) требуется указать лишь путь доступа к данным:
| TYPE | STANDARD |
| PATH | c:\users\data |
| TYPE | INTRBASE |
| PATH | |
| SERVER NAME | myserv:g:\users\contacts.gdb |
| USER NAME | SYSDBA |
| OPEN MODE | READ/WRITE |
| SCHEMA CACHE SIZE | 8 |
| LANGDRIVER | Pdox ANSI Cyrillic |
| SQLQRYMODE | |
| SQLPASSTHRU MODE | SHARED AUTOCOMMIT |
| SCHEMA CACHE TIME | -1 |
В этом примере база данных CONTACTS.GDB размещается в директории USERS, находящемся на диске G Windows NT сервера, называющегося MYSERV. Имя пользователя при связи с базой данных по этому алиасу - SYSDBA. Остальные параметры - LANGDRIVER, SQLQRYMODE, SQLPASSTHRU MODE, SCHEMA CACHE SIZE и SCHEMA CACHE TIME рассмотрим подробней.
Параметр LANGDRIVER определяет языковый драйвер для доступа к базе данных. Для правильной работы с русскими буквами при работе с базой данных формата dBase нужно выбрать значение “dBASE RUS cp866”, при работе с базами данных формата Paradox и SQL-серверами (в том числе InterBase) - “Pdox ANSI Cyrillic”. Кроме того, на этапе создания базы данных InterBase необходимо указать CHARACTER SET (набор символов) WIN1251.
Параметр SQLQRYMODE появляется только в случае, если установлен Borland SQL Links для связи с SQL-серверами. Он определяет режим передачи SQL-запросов и может иметь три значения: NULL (пустая строка - режим по умолчанию) - запрос сначала посылается на SQL-сервер. Если сервер не может выполнить запрос, последний обрабатывается локально (это актуально для распределенных баз данных); SERVER - запрос посылается на SQL-сервер. Если сервер не может выполнить запрос, генерируется ошибка; LOCAL - запрос всегда выполняется на рабочей станции. Параметр SQLPASSTHRU MODE определяет, могут ли запросы, передаваемые для выполнения на сервер (passthrouh SQL, использующие set-ориентированный подход), и стандартные вызовы BDE (использующие record-ориентированный навигационный подход) обрабатываться в одном и том же сеансе соединения с базой данных (в одном и том же “коннекте”) - быть “SHARED”. Он также может иметь три значения:
SHARED AUTOCOMMIT (значение по умолчанию) - для каждой операции по одной строке таблицы автоматически стартует неявная транзакция, которая, в случае успеха, завершается оператором COMMIT (закрепляющим произведенные изменения). Такой подход наилучшим образом подходит для работы с локальными базами, но неэффективен для SQL-серверных баз данных, так как стартующие каждый раз новые транзакции значительно загружают сетевой траффик. SHARED NOAUTOCOMMIT - приложение должно явно стартовать и завершать транзакцию. Эта установка может привести к конфликтам в многопользовательской среде, где большое количество пользователей пытаются обновить одну и ту же строку таблицы. NOT SHARED - означает, что запросы, передаваемые для выполнения на сервер (passthrouh SQL), и стандартные вызовы BDE (методы Delphi) используют раздельные соединения (“коннекты”) с базой данных. Для управления транзакциями через “passthrouh SQL” необходимо устанавливать именно это значение, иначе “passthrouh SQL” и методы Delphi могут интерферировать друг с другом, что, в свою очередь, может привести к непредсказуемым результатам. В параметре SCHEMA CACHE SIZE указывается число таблиц базы данных, информация о структуре которых будет кэшироваться, обеспечивая быстрый доступ к метаданным. Значение этого параметра может быть целым числом от 0 до 32. По умолчанию установлено число 8. Параметр SCHEMA CACHE TIME определяет время, в течение которого будет кэшироваться информация из таблиц базы данных. Может иметь следующие значения: -1 (значение по умолчанию) - информация из таблиц кэшируется до самого закрытия базы данных; 0 - информация из таблиц вообще не кэшируется; 1 - 2,147,483,647 - информация из таблиц кэшируется в течение указанного времени (в секундах). Напомним, что установки по умолчанию параметров SQLQRYMODE, SQLPASSTHRU MODE, SCHEMA CACHE SIZE и SCHEMA CACHE TIME обеспечивают достаточно оптимальный режим работы с базой данных. Экспериментировать с ними для достижения наибольшей эффективности работы с конкретной базой данных желательно только после накопления некоторого опыта работы с BDE.
Остановимся подробней на задании такого важного параметра, как SERVER NAME. В нем нужно указать не только имя сервера (на котором находится Ваша база данных) и полный путь доступа к базе, но и сетевой протокол. Создатели утилиты настройки BDE не сочли нужным выделять протокол в отдельный параметр, поэтому необходимо использовать следующие выражения: для доступа по протоколу TCP/IP - IB_SERVER:PATH\DATABASE.GDB.
Например, путь к базе на Windows NT сервере будет выглядеть следующим образом - mynt:c:\ib\base.gdb, а к базе на UNIX-сервере - myunix:/ib/base.gdb; для доступа по протоколу IPX/SPX - IB_SERVER@PATH\DATABASE.GDB.
Например: mynw@sys:ib\base.gdb; для доступа по протоколу NETBEUI - \\IB_SERVER\PATH\DATABASE.GDB.
Например: \\mynt\c:\ib\base.gdb. В этих примерах mynt - имя сервера Windows NT, myunix - имя сервера UNIX-системы, mynw - имя сервера Novell NetWare, sys - имя тома NetWare, ib - директорий, в котором находится база данных, base.gdb - имя базы данных InterBase. Для того чтобы правильно указать имя сервера Oracle, нужно писать имя по правилам Oracle - перед именем поставить @.
Замечание. При доступе к SQL-серверным базам данных параметр PATH должен оставаться пустым, иначе ядро баз данных не сможет определить истинный путь к Вашей базе, и будет сгенерирована ошибка.
Системная информация утилиты настройки BDE (BDECFG) Итак, мы познакомились с наиболее важной возможностью утилиты настройки BDE - созданием и редактированием алиасов, определяющих параметры доступа к базам данных. Однако, утилита настройки BDE позволяет специфицировать не только алиасы, но и драйверы для доступа к базам данных, а также различную системную информацию, составляющую операционное окружение этих самых алиасов. Системная информация располагается на страничках “System”, “Date”, “Time”, “Number”. Рассмотрим подробней эти странички. System: Определяет память и технические установки для таблиц в формате Paradox. Установленные по умолчанию значения обеспечивают оптимальные параметры работы с таблицами Paradox. Однако, если у Вас возникают проблемы, Вы можете изменить минимальный и максимальный размер кэш-буфера (MINBUFSIZE, MAXBUFSIZE; значения по умолчанию соответственно 128
и 2048 Кб - должны быть меньше размера физической памяти, доступной для Windows), а также максимальную величину стандартной (low) памяти, используемой BDE для доступа к базе (LOW MEMORY USAGE LIMIT, значение по умолчанию - 32 Кб). Вы можете также специфицировать языковый драйвер по умолчанию (LANGDRIVER), однако языковый драйвер, установленный в алиасе, имеет больший приоритет. Аналогичным образом (и с теми же оговорками относительно приоритета) Вы можете изменить параметр SQLQRYMODE, если у Вас установлен Borland SQL Links. С помощью параметра LOCAL SHARE можно управлять возможностью одновременного доступа к таблицам из разных приложений через BDE и не через BDE (например, с использованием своей библиотеки доступа). Значение по умолчанию - false, что означает запрет такой работы. Параметр AUTO ODBC определяет режим выборки параметров алиасов, основанных на ODBC-драйверах. Установленное по умолчанию значение false означает, что параметры берутся из конфигурационного файла BDE (IDAPI.CFG). Если Вы желаете брать ODBC-алиасы из файла ODBC.INI, установите этот параметр в true. Стоит упомянуть и о параметре DEFAULT DRIVER, который используется всякий раз, когда в названии таблицы отсутствует расширение и таблица имеет формат локальных СУБД. Остальные параметры (VERSION и SYSFLAGS) являются системными, и их не следует изменять. Date: Определяет установки, используемые при конвертации строковых значений в дату и обратно. Основаны на значениях, устанавливаемых для каждой страны и зафиксированных в файле WIN.INI (секция [intl]). Однако, все параметры формата даты, времени и чисел BDE берет не из конфигурационного файла BDE, куда попадают данные установки, а из соответствующих переменных модуля SysUtils. По-видимому, эта ситуация произошла по недосмотру разработчиков. Поэтому мы перечислим параметры страничек “Date”, “Time”, “Number” и укажем те переменные, которыми действительно можно управлять изменением системной информации. Среди параметров даты имеются следующие: SEPARATOR - символ, используемый для разделения дня, месяца и года в дате. Ему соответствует переменная DateSeparator
(Char*). Обычно имеет значения ‘.’, ‘-’, ‘/’. Значение по умолчанию берется из параметра sDate секции [intl] файла WIN.INI.
Time: Определяет установки, используемые при конвертации строковых значений во время и обратно. Также основаны на значениях, устанавливаемых для каждой страны и зафиксированных в файле WIN.INI (секция [intl]). Аналогично дате, для формата времени совместно с ShortDateFormat используются переменные LongTimeFormat
(обращаем внимание - именно LongTimeFormat, а не ShortTimeFormat) и TimeSeparator. Значения по умолчанию вычисляются по параметрам iTime и iTLZero секции [intl] файла WIN.INI. Кроме указанных переменных, для форматирования можно использовать переменные TimeAMString (основана на параметре s1159 секции [intl]) и TimePMString (основана на параметре s2359 секции [intl]). Number: Описывает трактовку чисел BDE. В частности, определяет символ для десятичной точки (переменная DecimalSeparator, основана на параметре sDecimal секции [intl]), разделитель для тысяч (переменная ThousandSeparator, основана на параметре sThousand секции [intl]), количество знаков после запятой (переменная CurrencyDecimals, основана на параметре sCurrDigits секции [intl]) и наличие лидирующих нулей. Как уже отмечалось выше, утилита настройки BDE сохраняет всю конфигурационную информацию в файле IDAPI.CFG. Этот файл с предустановленными ссылками на драйверы и некоторыми стандартными алиасами создается при установке Delphi. Кроме того, он создается при установке файлов редистрибуции BDE (т.е. когда Вы переносите BDE и SQL Links на другие компьютеры). Установка драйверов ODBC и других драйверов
При установке SQL Links для какого-либо SQL-сервера Вам не требуется “вручную” добавлять драйверы связи с этим сервером - программа установки SQL Links сделает это автоматически. Заметим, что при установке Delphi Client-Server автоматически устанавливаются также и SQL Links, так что отдельно их инсталляцию проводить не требуется. Вам останется только подправить некоторые параметры (например, языковый драйвер) для установленных драйверов. Но кроме “родных” SQL Links, для доступа к SQL-серверам (и локальным базам данных) можно использовать ODBC-драйверы.
Delphi использует Microsoft 2.0 ODBC Driver Manager. Если Вы имеете версию ODBC Driver Manager, отличную от указанной - сохраните существующие файлы ODBC.DLL и ODBCINST.DLL и скопируйте файлы ODBC.NEW и ODBCINST.NEW из директория IDAPI в Ваш ODBC-директорий (по умолчанию, это поддиректорий SYSTEM в “виндусовом” директории) и переименуйте их соответственно в ODBC.DLL и ODBCINST.DLL.


Установка ODBC-драйвера начинается с проверки того, какие драйверы уже находятся в Вашей системе. Для этого в Панели Управления (Control Panel) найдите иконку “ODBC” (рис. 4), которая запускает утилиту конфигурации ODBC. В ее диалоговом окне представлен список ODBC-алиасов (Data Source) с указанием в скобках ODBC-драйверов, на которых они основаны (рис. 5).

Для создания нового ODBC-алиаса сначала нужно выбрать ODBC-драйвер. Для этого нажмите кнопку “Add”, имеющуюся в правой части диалогового окна “Data Sources”, изображенного на рис. 5. Если в списке установленных ODBC-драйверов не окажется нужного Вам драйвера, вернитесь к окну “Data Sources” и установите новый драйвер, указав его местонахождение (с помощью кнопки “Drivers”). После выбора ODBC-драйвера перед Вами появится диалоговое окно, содержимое которого зависит от выбранного Вами драйвера (рис. 6) и в котором Вы сможете произвести настройку ODBC-алиаса, определив его имя (Data Source Name), выбрав версию продукта и указав директорий, в котором находятся файлы базы данных. После нажатия кнопки “OK” ODBC-алиас будет создан, и Вы вернетесь в окно “Data Sources” (рис. 5).

Следующий шаг состоит в создании BDE-надстройки над ODBC-алиасом. Для этого Вам нужно убедиться, что в Вашем директории IDAPI имеется файл IDODBC01.DLL - в противном случае нужно заново установить BDE. После этого можно загрузить утилиту настройки BDE. Если Вы нажмете кнопку “New ODBC Driver” на страничке “Drivers”, Вы увидите диалоговое окно, изображенное на рис.7. Название BDE-драйвера, основанного на ODBC-алиасе, по умолчанию, должно начинаться с букв “ODBC_”. Поэтому такие буквы уже вынесены перед названием драйвера, так что Вам не нужно их вводить. Введите любое название драйвера и выберите из выпадающих списков сначала ODBC-драйвер, а затем - созданный Вами на его основе ODBC-алиас (Default Data Source Name).
Таким образом, мы создали BDE-драйвер, основанный на ODBC-алиасе. После этого BDE-алиас создается стандартным способом, который мы рассмотрели выше. Заключение Итак, на данном уроке мы изучили очень важное для работы с базами данных понятие - алиас, а также научились настраивать его параметры для корректной работы программы. Кроме того, изучены многие вопросы, касающиеся настройки системных параметров. Очень важной для совместимости с базами данных третьих фирм является возможность создавать ODBC-алиасы и работать с ними стандартными средствами BDE. В этот вопрос мы также постарались внести ясность.
На данном уроке мы изучим,
32 урока по Delphi

Урок 17: Создание таблиц с помощью Database Desktop
Содержание урока 17:
Обзор
Утилита Database Desktop
Заключение Обзор
На данном уроке мы изучим, как создавать таблицы базы данных с помощью утилиты Database Desktop, входящей в поставку Delphi. Хотя для создания таблиц можно использовать различные средства (SQL - компонент TQuery и WISQL, компонент TTable), применение этой утилиты позволяет создавать таблицы в интерактивном режиме и сразу же просмотреть их содержимое - и все это для большого числа форматов. Это особенно удобно для локальных баз данных, в частности Paradox и dBase. Утилита Database Desktop

Database Desktop - это утилита, во многом похожая на Paradox, которая поставляется вместе с Delphi для интерактивной работы с таблицами различных форматов локальных баз данных - Paradox и dBase, а также SQL-серверных баз данных InterBase, Oracle, Informix, Sybase (с использованием SQL Links). Исполняемый файл утилиты называется DBD.EXE, расположен он, как правило, в директории, называемом DBD (при установке по умолчанию). Для запуска Database Desktop просто дважды щелкните по ее иконке.

После старта Database Desktop выберите команду меню File|New|Table для создания новой таблицы. Перед Вами появится диалоговое окно выбора типа таблицы, как показано на рис.1. Вы можете выбрать любой формат из предложенного, включая различные версии одного и того же формата.
После выбора типа таблицы Database Desktop представит Вам диалоговое окно, специфичное для каждого формата, в котором Вы сможете определить поля таблицы и их тип, как показано на рис.2.
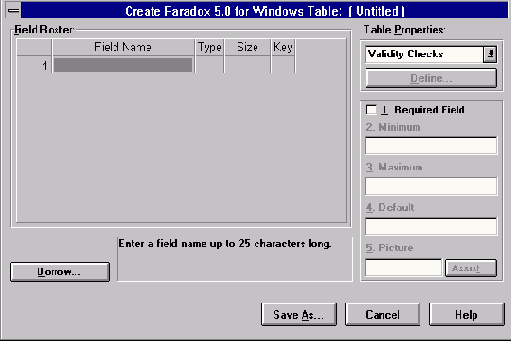
Имя поля в таблице формата Paradox представляет собой строку, написание которой подчиняется следующим правилам:
Имя должно быть не длиннее 25 символов. Имя не должно начинаться с пробела, однако может содержать пробелы. Однако, если Вы предполагаете в будущем переносить базу данных в другие форматы, разумнее будет избегать включения пробелов в название поля. Фактически, в целях переносимости лучше ограничиться девятью символами в названии поля, не включая в него пробелы.
Имя не должно содержать квадратные, круглые или фигурные скобки [], () или {}, тире, а также комбинацию символов “тире” и “больше” (->). Имя не должно быть только символом #, хотя этот символ может присутствовать в имени среди других символов. Хотя Paradox поддерживает точку (.) в названии поля, лучше ее избегать, поскольку точка зарезервирована в Delphi для других целей. Имя поля в таблице формата dBase представляет собой строку, написание которой подчиняется правилам, отличным от Paradox: Имя должно быть не длиннее 10 символов. Пробелы в имени недопустимы. Таким образом, Вы видите, что имена полей в формате dBase подчиняются гораздо более строгим правилам, нежели таковые в формате Paradox. Однако, мы еще раз хотим подчеркнуть, что если перед Вами когда-либо встанут вопросы совместимости, то лучше сразу закладывать эту совместимость - давать полям имена, подчиняющиеся более строгим правилам. Укажем еще правила, которым подчиняется написание имен полей в формате InterBase. Имя должно быть не длиннее 31 символа. Имя должно начинаться с букв A-Z, a-z. Имя поля может содержать буквы (A-Z, a-z), цифры, знак $ и символ подчеркивания (_). Пробелы в имени недопустимы. Для имен таблиц запрещается использовать зарезервированные слова InterBase. Следующий (после выбора имени поля) шаг состоит в задании типа поля. Типы полей очень сильно различаются друг от друга, в зависимости от формата таблицы. Для получения списка типов полей перейдите к столбцу “Type”, а затем нажмите пробел или щелкните правой кнопкой мышки. Приведем списки типов полей, характерные для форматов Paradox, dBase и InterBase.
Итак, поля таблиц формата Paradox могут иметь следующий тип (для ввода типа поля можно набрать только подчеркнутые буквы или цифры):
Табл. A: Типы полей формата Paradox
| Alpha | строка длиной 1-255 байт, содержащая любые печатаемые символы |
| Number | числовое поле длиной 8 байт, значение которого может быть положительным и отрицательным. Диапазон чисел - от 10-308 до 10308 с 15 значащими цифрами |
| $ (Money) | числовое поле, значение которого может быть положительным и отрицательным. По умолчанию, является форматированным для отображения десятичной точки и денежного знака |
| Short | числовое поле длиной 2 байта, которое может содержать только целые числа в диапазоне от -32768 до 32767 |
| Long Integer | числовое поле длиной 4 байта, которое может содержать целые числа в диапазоне от -2147483648 до 2147483648 |
| # (BCD) | числовое поле, содержащее данные в формате BCD (Binary Coded Decimal). Скорость вычислений немного меньше, чем в других числовых форматах, однако точность - гораздо выше. Может иметь 0-32 цифр после десятичной точки |
| Date | поле даты длиной 4 байта, которое может содержать дату от 1 января 9999 г. до нашей эры - до 31 декабря 9999 г. нашей эры. Корректно обрабатывает високосные года и имеет встроенный механизм проверки правильности даты |
| Time | поле времени длиной 4 байта, содержит время в миллисекундах от полуночи и ограничено 24 часами |
| @ (Timestamp) | обобщенное поле даты длиной 8 байт - содержит и дату и время |
| Memo | поле для хранения символов, суммарная длина которых более 255 байт. Может иметь любую длину. При этом размер, указываемый при создании таблицы, означает количество символов, сохраняемых в таблице (1-240) - остальные символы сохраняются в отдельном файле с расширением .MB |
| Formatted Memo | поле, аналогичное Memo, с добавлением возможности задавать шрифт текста. Также может иметь любую длину. При этом размер, указываемый при создании таблицы, означает количество символов, сохраняемых в таблице (0-240) - остальные символы сохраняются в отдельном файле с расширением .MB. Однако, Delphi в стандартной поставке не обладает возможностью работать с полями типа Formatted Memo |
| Graphic | поле, содержащее графическую информацию. Может иметь любую длину. Смысл размера - такой же, как и в Formatted Memo. Database Desktop “умеет” создавать поля типа Graphic, однако наполнять их можно только в приложении |
| OLE | поле, содержащее OLE-данные (Object Linking and Embedding) - образы, звук, видео, документы - которые для своей обработки вызывают создавшее их приложение. Может иметь любую длину. Смысл размера - такой же, как и в Formatted Memo. Database Desktop “умеет” создавать поля типа OLE, однако наполнять их можно только в приложении. Delphi “напрямую” не умеет работать с OLE-полями, но это легко обходится путем использования потоков |
| Logical | поле длиной 1 байт, которое может содержать только два значения - T (true, истина) или F (false, ложь). Допускаются строчные и прописные буквы |
| + (Autoincrement) | поле длиной 4 байта, содержащее нередактируемое (read-only) значение типа long integer. Значение этого поля автоматически увеличивается (начиная с 1) с шагом 1 - это очень удобно для создания уникального идентификатора записи (физический номер записи не может служить ее идентификатором, поскольку в Парадоксе таковой отсутствует. В InterBase также отсутствуют физические номера записей, но отсутствует и поле Autoincrement. Его с успехом заменяет встроенная функция Gen_id, которую удобней всего применять в триггерах) |
| Binary | поле, содержащее любую двоичную информацию. Может иметь любую длину. При этом размер, указываемый при создании таблицы, означает количество символов, сохраняемых в таблице (0-240) - остальные символы сохраняются в отдельном файле с расширением .MB. Это полнейший аналог поля BLOb в InterBase |
| Bytes | строка цифр длиной 1-255 байт, содержащая любые данные |
Поля таблиц формата dBase могут иметь следующий тип (для ввода типа поля можно набрать только подчеркнутые буквы или цифры):
Табл. B: Типы полей формата dBase
| Character (alpha)строка длиной 1-254 байт, содержащая любые печатаемые символы | |
| Float (numeric) | числовое поле размером 1-20 байт в формате с плавающей точкой, значение которого может быть положительным и отрицательным. Может содержать очень большие величины, однако следует иметь в виду постоянные ошибки округления при работе с полем такого типа. Число цифр после десятичной точки (параметр Dec в DBD) должно быть по крайней мере на 2 меньше, чем размер всего поля, поскольку в общий размер включаются сама десятичная точка и знак |
| Number (BCD) | числовое поле размером 1-20 байт, содержащее данные в формате BCD (Binary Coded Decimal). Скорость вычислений немного меньше, чем в других числовых форматах, однако точность - гораздо выше. Число цифр после десятичной точки (параметр Dec в DBD) также должно быть по крайней мере на 2 меньше, чем размер всего поля, поскольку в общий размер включаются сама десятичная точка и знак |
| Date | поле даты длиной 8 байт. По умолчанию, используется формат короткой даты (ShortDateFormat) |
| Logical | поле длиной 1 байт, которое может содержать только значения “истина” или “ложь” - T,t,Y,y (true, истина) или F,f,N,n (false, ложь). Допускаются строчные и прописные буквы. Таким образом, в отличие от Парадокса, допускаются буквы “Y” и “N” (сокращение от Yes и No) |
| Memo | поле для хранения символов, суммарная длина которых более 255 байт. Может иметь любую длину. Это поле хранится в отдельном файле. Database Desktop не имеет возможности вставлять данные в поле типа Memo |
| OLE | поле, содержащее OLE-данные (Object Linking and Embedding) - образы, звук, видео, документы - которые для своей обработки вызывают создавшее их приложение. Может иметь любую длину. Это поле также сохраняется в отдельном файле. Database Desktop “умеет” создавать поля типа OLE, однако наполнять их можно только в приложении. Delphi “напрямую” не умеет работать с OLE-полями, но это легко обходится путем использования потоков |
| Binary | поле, содержащее любую двоичную информацию. Может иметь любую длину. Данное поле сохраняется в отдельном файле с расширением .DBT. Это полнейший аналог поля BLOb в InterBase |
Поля таблиц формата InterBase могут иметь следующий тип:
Табл. C: Типы полей формата InterBase
| SHORT | числовое поле длиной 2 байта, которое может содержать только целые числа в диапазоне от -32768 до 32767 |
| LONG | числовое поле длиной 4 байта, которое может содержать целые числа в диапазоне от -2147483648 до 2147483648 |
| FLOAT | числовое поле длиной 4 байта, значение которого может быть положительным и отрицательным. Диапазон чисел - от 3.4*10-38 до 3.4*1038 с 7 значащими цифрами |
| DOUBLE | числовое поле длиной 8 байт (длина зависит от платформы), значение которого может быть положительным и отрицательным. Диапазон чисел - от 1.7*10-308 до 1.7*10308 с 15 значащими цифрами |
| CHAR | строка символов фиксированной длины (0-32767 байт), содержащая любые печатаемые символы. Число символов зависит от Character Set, установленного в InterBase для данного поля или для всей базы данных (например, для символов в кодировке Unicode число символов будет в два раза меньше длины строки) |
| VARCHAR | строка символов переменной длины (0-32767 байт), содержащая любые печатаемые символы. Число символов также зависит от Character Set, установленного в InterBase для данного поля или для всей базы данных |
| DATE | поле даты длиной 8 байт, значение которого может быть от 1 января 100 года до 11 декабря 5941 года (время также содержится) |
| BLOB | поле, содержащее любую двоичную информацию. Может иметь любую длину. Database Desktop не имеет возможности редактировать поля типа BLOB |
| ARRAY | поле, содержащее массивы данных. InterBase позволяет определять массивы, имеющие размерность 16. Поле может иметь любую длину. Однако, Database Desktop не имеет возможности не только редактировать поля типа ARRAY, но и создавать их |
| TEXT BLOB | подтип BLOB-поля, содержащее только текстовую информацию. Может иметь любую длину. Database Desktop не имеет возможности редактировать поля типа TEXT BLOB |
Итак, мы изучили все типы полей, являющиеся “родными” для Delphi.
После этого для таблиц Paradox мы можем определить поля, составляющие первичный ключ, причем все они должны быть в начале записи, а первое поле, входящее в ключ, должно быть первым полем в записи. Для этого достаточно по ней дважды щелкнуть мышкой или нажать любую клавишу.
После создания таблицы, с ней можно связать некоторые свойства, перечень которых зависит от формата таблицы. Так, для таблиц формата Paradox можно задать: Validity Checks (проверка правильности) - относится к полю записи и определяет минимальное и максимальное значение, а также значение по умолчанию. Кроме того, позволяет задать маску ввода Table Lookup (таблица для “подсматривания”) - позволяет вводить значение в таблицу, используя уже существующее значение в другой таблице Secondary Indexes (вторичные индексы) - позволяют доступаться к данным в порядке, отличном от порядка, задаваемого первичным ключом Referential Integrity (ссылочная целостность) - позволяет задать связи между таблицами и поддерживать эти связи на уровне ядра. Обычно задается после создания всех таблиц в базе данных Password Security (парольная защита) - позволяет закрыть таблицу паролем Table Language (язык таблицы) - позволяет задать для таблицы языковый драйвер. В таблицах dBase не существует первичных ключей. Однако, это обстоятельство можно преодолеть путем определения уникальных (Unique) и поддерживаемых (Maintained) индексов (Indexes). Кроме того, для таблиц dBase можно определить и язык таблицы (Table Language) - языковый драйвер, управляющий сортировкой и отображением символьных данных.
Определения дополнительных свойств таблиц всех форматов доступны через кнопку “Define” (для таблиц InterBase данная кнопка называется “Define Index...” и позволяет определять лишь только индекс, но не первичный ключ) в правой верхней части окна (группа Table Properties). Причем, все эти действия можно проделывать не только при создании таблицы, но и тогда, когда она уже существует. Для этого используется команда Table|Restructure Table (для открытой в данный момент таблицы) или Utilities|Restructure (с возможностью выбора таблицы). Однако, если Вы желаете изменить структуру или добавить новые свойства для таблицы, которая в данный момент уже используется другим приложением, Database Desktop откажет Вам в этом, поскольку данная операция требует монопольного доступа к таблице. Но зато все произведенные в структуре изменения сразу же начинают “работать” - например, если Вы определите ссылочную целостность для пары таблиц, то при попытке вставить в дочернюю таблицу данные, отсутствующие в родительской таблице, в Delphi возникнет исключительное состояние.
В заключение отметим еще часто используемую очень полезную возможность Database Desktop. Создавать таблицу любого формата можно не только “с чистого листа”, но и путем копирования структуры уже существующей таблицы. Для этого достаточно воспользоваться кнопкой “Borrow”, имеющейся в левом нижнем углу окна. Появляющееся диалоговое окно позволит Вам выбрать существующую таблицу и включить/выключить дополнительные опции, совпадающие с уже перечисленными свойствами таблиц. Это наиболее легкий способ создания таблиц. Заключение Итак, на данном уроке мы познакомились со штатной утилитой, используемой для интерактивного создания и модификации таблиц различной структуры. И хотя управление таблицами можно осуществлять с помощью различных средств (SQL-скрипт в WISQL, компонент TTable, компонент TQuery), данная утилита позволяет делать это в интерактивном режиме наиболее простым способом.
На данном уроке мы познакомимся
32 урока по Delphi

Урок 18: Создание таблиц с помощью SQL-запросов
Содержание урока 18:
Обзор
Создание таблиц с помощью SQL
Заключение
Обзор

На данном уроке мы познакомимся еще с одной возможностью создания таблиц - через посылку SQL-запросов. Как Вы, наверное, могли заметить на предыдущем уроке, Database Desktop не обладает всеми возможностями по управлению SQL-серверными базами данных. Поэтому с помощью Database Desktop удобно создавать или локальные базы данных или только простейшие SQL-серверные базы данных, состоящие из небольшого числа таблиц, не очень сильно связанных друг с другом. Если же Вам необходимо создать базу данных, состоящую из большого числа таблиц, имеющих сложные взаимосвязи, можно воспользоваться языком SQL (вообще говоря, для этих целей лучше всего использовать специализированные CASE-средства, которые позволяют в интерактивном режиме сгенерировать всю структуру базы данных и сформировать все связи; описание двух наиболее удачных CASE-средств - System Architect и S-Designor - дано в дополнительных уроках). При этом можно воспользоваться компонентом Query в Delphi, каждый раз посылая по одному SQL-запросу, а можно записать всю последовательность SQL-предложений в один так называемый скрипт и послать его на выполнение, используя, например, Windows Interactive SQL (WISQL.EXE) - интерактивное средство посылки SQL-запросов к InterBase (в том числе и локальному InterBase), входящее в поставку Delphi. Конечно, для этого нужно хорошо знать язык SQL, но, уверяю Вас, сложного в этом ничего нет! Конкретные реализации языка SQL незначительно отличаются в различных SQL-серверах, однако базовые предложения остаются одинаковыми для всех реализаций. Практика показывает, что если нет необходимости создавать таблицы во время выполнения программы, то лучше воспользоваться WISQL. Создание таблиц с помощью SQL
Если Вы хотите воспользоваться компонентом TQuery, сначала поместите его на форму. После этого настройте свойство DatabaseName
на нужный Вам алиас ( если базы данных еще не существует, удобней создать ее в WISQL командой File|Create Database..., а затем уже настроить на нее новый алиас). После этого можно ввести SQL-предложение в свойство SQL. Для выполнения запроса, изменяющего структуру, вставляющего или обновляющего данные на сервере, нужно вызвать метод ExecSQL компонента TQuery. Для выполнения запроса, получающего данные с сервера (т.е. запроса, в котором основным является оператор SELECT), нужно вызвать метод Open компонента TQuery. Это связано с тем, что BDE при посылке запроса типа SELECT открывает так называемый курсор, с помощью которого осуществляется навигация по выборке данных (подробней об этом см. в уроке, посвященном TQuery). Как показывает опыт, проще воспользоваться утилитой WISQL. Для этого в WISQL выберите команду File|Run an ISQL Script... и выберите файл, в котором записан ваш скрипт, создающий базу данных. После нажатия кнопки “OK” ваш скрипт будет выполнен, и в нижнее окно будет выведен протокол его работы.
Приведем упрощенный синтаксис SQL-предложения для создания таблицы на SQL-сервере InterBase (более полный синтаксис можно посмотреть в online-справочнике по SQL, поставляемом с локальным InterBase):
CREATE TABLE table
(<col_def> [, <col_def> | <tconstraint> ...]);
где
table - имя создаваемой таблицы,
<col_def> - описание поля,
<tconstraint> - описание ограничений и/или ключей (квадратные скобки [] означают необязательность, вертикальная черта | означает “или”).
Описание поля состоит из наименования поля и типа поля (или домена - см. урок 9), а также дополнительных ограничений, накладываемых на поле:
<col_def> = col {datatype | COMPUTED BY (<expr>) | domain}
[DEFAULT {literal | NULL | USER}]
[NOT NULL] [<col_constraint>]
[COLLATE collation]
Здесь
col - имя поля;
datatype - любой правильный тип SQL-сервера (для InterBase такими типами являются - см. урок 11 - SMALLINT, INTEGER, FLOAT, DOUBLE PRECISION, DECIMAL, NUMERIC, DATE, CHAR, VARCHAR, NCHAR, BLOB), символьные типы могут иметь CHARACTER SET - набор символов, определяющий язык страны. Для русского языка следует задать набор символов WIN1251;
COMPUTED BY (<expr>) - определение вычисляемого на уровне сервера поля, где <expr> - правильное SQL-выражение, возвращающее единственное значение;
domain - имя домена (обобщенного типа), определенного в базе данных;
DEFAULT - конструкция, определяющая значение поля по умолчанию;
NOT NULL - конструкция, указывающая на то, что поле не может быть пустым;
COLLATE - предложение, определяющее порядок сортировки для выбранного набора символов (для поля типа BLOB не применяется). Русский набор символов WIN1251 имеет 2 порядка сортировки - WIN1251 и PXW_CYRL. Для правильной сортировки, включающей большие буквы, следует выбрать порядок PXW_CYRL.
Описание ограничений и/или ключей включает в себя предложения CONSTRAINT или предложения, описывающие уникальные поля, первичные, внешние ключи, а также ограничения CHECK (такие конструкции могут определяться как на уровне поля, так и на уровне таблицы в целом, если они затрагивают несколько полей):
<tconstraint> = [CONSTRAINT constraint <tconstraint_def>]
<tconstraint>
Здесь
<tconstraint_def> = {{PRIMARY KEY | UNIQUE} (col[,col...]) | FOREIGN KEY (col [, col ...]) REFERENCES other_table
| CHECK (<search_condition>)}
<search_condition> =
{<val> <operator> {<val> | (<select_one>)}
| <val> [NOT] BETWEEN <val> AND <val>
| <val> [NOT] LIKE <val> [ESCAPE <val>]
| <val> [NOT] IN (<val> [, <val> ...] |
<val> = {
col [<array_dim>] | <constant> | <expr> | <function>
| NULL | USER | RDB$DB_KEY } [COLLATE collation]
<constant> = num | "string" | charsetname "string"
<function> = {
COUNT (* | [ALL] <val> | DISTINCT <val>)
| SUM ([ALL] <val> | DISTINCT <val>)
| AVG ([ALL] <val> | DISTINCT <val>)
| MAX ([ALL] <val> | DISTINCT <val>)
| MIN ([ALL] <val> | DISTINCT <val>)
| CAST (<val> AS <datatype>)
| UPPER (<val>)
| GEN_ID (generator, <val>)
}
<operator> = {= | < | > | <= | >= | !< | !> | <> | !=}
<select_one> = выражение SELECT по одному полю, которое возвращает в точности одно значение.
Приведенного неполного синтаксиса достаточно для большинства задач, решаемых в различных предметных областях. Проще всего синтаксис SQL можно понять из примеров. Поэтому мы приведем несколько примеров создания таблиц с помощью SQL.
Пример A: Простая таблица с конструкцией PRIMARY KEY на уровне поля
CREATE TABLE REGION (
REGION REGION_NAME NOT NULL PRIMARY KEY,
POPULATION INTEGER NOT NULL);
Предполагается, что в базе данных определен домен REGION_NAME, например, следующим образом:
CREATE DOMAIN REGION_NAME
AS VARCHAR(40) CHARACTER SET WIN1251 COLLATE PXW_CYRL;
Пример B: Таблица с предложением UNIQUE как на уровне поля, так и на уровне таблицы
CREATE TABLE GOODS (
MODEL SMALLINT NOT NULL UNIQUE,
NAME CHAR(10) NOT NULL,
ITEMID INTEGER NOT NULL, CONSTRAINT MOD_UNIQUE
UNIQUE (NAME, ITEMID));
Пример C: Таблица с определением первичного ключа, внешнего ключа и конструкции CHECK, а также символьных массивов
CREATE TABLE JOB (
JOB_CODE JOBCODE NOT NULL,
JOB_GRADE JOBGRADE NOT NULL,
JOB_REGION REGION_NAME NOT NULL,
JOB_TITLE VARCHAR(25) CHARACTER SET WIN1251 COLLATE PXW_CYRL NOT NULL,
MIN_SALARY SALARY NOT NULL,
MAX_SALARY SALARY NOT NULL,
JOB_REQ BLOB(400,1) CHARACTER SET WIN1251,
LANGUAGE_REQ VARCHAR(15) [5],
PRIMARY KEY (JOB_CODE, JOB_GRADE, JOB_REGION),
FOREIGN KEY (JOB_REGION) REFERENCES REGION (REGION),
CHECK (MIN_SALARY < MAX_SALARY));
Данный пример создает таблицу, содержащую информацию о работах (профессиях). Типы полей основаны на доменах JOBCODE, JOBGRADE, REGION_NAME и SALARY. Определен массив LANGUAGE_REQ, состоящий из 5 элементов типа VARCHAR(15). Кроме того, введено поле JOB_REQ, имеющее тип BLOB с подтипом 1 (текстовый блоб) и размером сегмента 400. Для таблицы определен первичный ключ, состоящий из трех полей JOB_CODE, JOB_GRADE и JOB_REGION. Далее, определен внешний ключ (JOB_REGION), ссылающийся на поле REGION таблицы REGION. И, наконец, включено предложение CHECK, позволяющее производить проверку соотношения для двух полей и вызывать исключительное состояние при нарушении такого соотношения.
Пример D: Таблица с вычисляемым полем
CREATE TABLE SALARY_HISTORY (
EMP_NO EMPNO NOT NULL,
CHANGE_DATE DATE DEFAULT "NOW" NOT NULL,
UPDATER_ID VARCHAR(20) NOT NULL,
OLD_SALARY SALARY NOT NULL,
PERC_CHANGE DOUBLE PRECISION DEFAULT 0 NOT NULL
CHECK (PERC_CHANGE BETWEEN -50 AND 50),
NEW_SALARY COMPUTED BY
(OLD_SALARY + OLD_SALARY * PERC_CHANGE / 100),
PRIMARY KEY (EMP_NO, CHANGE_DATE, UPDATER_ID),
FOREIGN KEY (EMP_NO) REFERENCES EMPLOYEE (EMP_NO));
Данный пример создает таблицу, где среди других полей имеется вычисляемое (физически не существующее) поле NEW_SALARY, значение которого вычисляется по значениям двух других полей (OLD_SALARY и PERC_CHANGE).
На диске приведен пример скрипта, создающего базу данных, осуществляющую ведение контактов между людьми и организациями.
Заключение Итак, мы рассмотрели, как создавать таблицы с помощью SQL-выражений. Этот процесс, хотя и не столь удобен, как интерактивное средство Database Desktop, однако обладает наиболее гибкими возможностями по настройке Вашей системы и управления ее связями.
Использование фильтров для ограничения числа

Урок 19: ОбъектTTable
Содержание урока 19:
Обзор Класс TDataSet Открытие и закрытие DataSet Навигация (Перемещение по записям) Поля Изменение Данных Использование SetKey для Поиска в таблице Использование фильтров для ограничения числа записей в DataSet Обновление Закладки Создание связанных курсоров Основные понятия TDataSource Использование TDataSource для проверки состояния БД Отслеживание состояния DataSet
ex19.zip Обзор Статья содержит всесторонний обзор основных фактов которые Вы должны знать, прежде чем начать писать программы, работающие с Базами Данных (БД). Прочитав эту статью, Вы должны понять большинство механизмов доступа к данным, которые есть в Delphi. Более подробно здесь рассказывается о TTable и TDataSource.
Имеются несколько основных компонент(объектов), которые Вы будете использовать постоянно для доступа к БД. Эти объекты могут быть разделены на три группы: невизуальные: TTable, TQuery, TDataSet, TField визуальные: TDBGrid, TDBEdit связующие: TDataSource Первая группа включает невизуальные классы, которые используются для управления таблицами и запросами. Эта группа сосредотачивается вокруг компонент типа TTable, TQuery, TDataSet и TField. В Палитре Компонент эти объекты расположены на странице Data Access.
Вторая важная группа классов - визуальные, которые показывают данные пользователю, и позволяют ему просматривать и модифицировать их. Эта группа классов включает компоненты типа TDBGrid, TDBEdit, TDBImage и TDBComboBox. В Палитре Компонент эти объекты расположены на странице Data Controls.
Имеется и третий тип, который используется для того, чтобы связать предыдущие два типа объектов. К третьему типу относится только невизуальный компонент TDataSource.
Класс TDataSet
TDataSet класс - один из наиболее важных объектов БД. Чтобы начать работать с ним, Вы должны взглянуть на следующую иерархию:
TDataSet
|
TDBDataSet
|
|-- TTable
|-- TQuery
|-- TStoredProc
TDataSet содержит абстрактные методы там, где должно быть непосредственное управление данными. TDBDataSet знает, как обращаться с паролями и то, что нужно сделать, чтобы присоединить Вас к определенной таблице. TTable знает (т.е. уже все абстрактные методы переписаны), как обращаться с таблицей, ее индексами и т.д.
Как Вы увидите в далее, TQuery имеет определенные методы для обработки SQL запросов.
TDataSet - инструмент, который Вы будете использовать чтобы открыть таблицу, и перемещаться по ней. Конечно, Вы никогда не будете непосредственно создавать объект типа TDataSet. Вместо этого, Вы будете использовать TTable, TQuery или других потомков TDataSet (например, TQBE). Полное понимание работы системы, и точное значение TDataSet, будут становиться все более ясными по мере прочтения этой главы.
На наиболее фундаментальном уровне, Dataset это просто набор записей, как изображено на рис.1
Рис.1: Любой dataset состоит из ряда записей (каждая содержит N полей) и указатель на текущую запись.
В большинстве случаев dataset будет иметь a прямое, один к одному, соответствие с физической таблицей, которая существует на диске. Однако, в других случаях Вы можете исполнять запрос или другое действие, возвращающие dataset, который содержит либо любое подмножество записей одной таблицы, либо объединение (join) между несколькими таблицами. В тексте будут иногда использоваться термины DataSet и TTable как синонимы.
Обычно в программе используются объекты типа TTable или TQuery, поэтому в следующих нескольких главах будет предполагаться существование объекта типа TTable называемого Table1.
Итак, самое время начать исследование TDataSet. Как только Вы познакомитесь с его возможностями, Вы начнете понимать, какие методы использует Delphi для доступа к данным, хранящимся на диске в виде БД. Ключевой момент здесь - не забывать, что почти всякий раз, когда программист на Delphi открывает таблицу, он будет использовать TTable или TQuery, которые являются просто некоторой надстройкой над TDataSet.
Открытие и закрытие DataSet В этой главе Вы узнаете некоторые факты об открытии и закрытии DataSet. Если Вы используете TTable для доступа к таблице, то при открытии данной таблицы заполняются некоторые свойства TTable (количество записей RecordCount, описание структуры таблицы и т.д.).
Прежде всего, Вы должны поместить во время дизайна на форму объект TTable и указать, с какой таблицей хотите работать. Для этого нужно заполнить в Инспекторе объектов свойства DatabaseName и TableName. В DatabaseName можно либо указать директорию, в которой лежат таблицы в формате dBase или Paradox (например, C:\DELPHI\DEMOS\DATA), либо выбрать из списка псевдоним базы данных (DBDEMOS). Псевдоним базы данных (Alias) определяется в утилите Database Engine Configuration. Теперь, если свойство Active установить в True, то при запуске приложения таблица будет открываться автоматически.
Имеются два различных способа открыть таблицу во время выполнения программы. Вы можете написать следующую строку кода:
Table1.Open;
Или, если Вы предпочитаете, то можете установить свойство Active равное True:
Table1.Active := True;
Нет никакого различия между результатом производимым этими двумя операциями. Метод Open, однако, сам заканчивается установкой свойства Active в True, так что может быть даже чуть более эффективно использовать свойство Active напрямую.
Также, как имеются два способа открыть a таблицу, так и есть два способа закрыть ее. Самый простой способ просто вызывать Close:
Table1.Close;
Или, если Вы желаете, Вы можете написать:
Table1.Active := False;
Еще раз повторим, что нет никакой существенной разницы между двумя этими способами. Вы должны только помнить, что Open и Close это методы (процедуры), а Active - свойство.
Навигация (Перемещение по записям)
После открытия a таблицы, следующим шагом Вы должны узнать как перемещаться по записям внутри него.
Следующий обширный набор методов и свойства TDataSet обеспечивает все , что Вам нужно для доступа к любой конкретной записи внутри таблицы:
procedure First;
procedure Last;
procedure Next;
procedure Prior;
property BOF: Boolean read FBOF;
property EOF: Boolean read FEOF;
procedure MoveBy(Distance: Integer);
Дадим краткий обзор их функциональных возможностей: Вызов Table1.First перемещает Вас к первой записи в таблице. Table1.Last перемещает Вас к последней записи. Table1.Next перемещает Вас на одну запись вперед. Table1.Prior перемещает Вас на одну запись Назад. Вы можете проверять свойства BOF или EOF, чтобы понять, находитесь ли Вы в начале или в конце таблицы. Процедура MoveBy перемещает Вас на N записей вперед или назад в таблице. Нет никакого функционального различия между запросом Table1.Next и вызовом Table1.MoveBy(1). Аналогично, вызов Table1.Prior имеет тот же самый результат, что и вызов Table1.MoveBy(-1). Чтобы начать использовать эти навигационные методы, Вы должны поместить TTable, TDataSource и TDBGrid на форму, также, как Вы делали это в предыдущем уроке. Присоедините DBGrid1 к DataSource1, и DataSource1 к Table1. Затем установите свойства таблицы: в DatabaseName имя подкаталога, где находятся демонстрационные таблицы (или псевдоним DBDEMOS); в TableName установите имя таблицы CUSTOMER. Если Вы запустили программу, которая содержит видимый элемент TDBGrid, то увидите, что можно перемещаться по записям таблицы с помощью полос прокрутки (scrollbar) на нижней и правой сторонах DBGrid.
Однако, иногда нужно перемещаться по таблице “программным путем”, без использования возможностей, встроенных в визуальные компоненты. В следующих нескольких абзацах объясняется как можно это сделать.
Поместите две кнопки на форму и назовите их Next и Prior, как показано на рис.2.

Рис.2 : Next и Prior кнопки позволяют Вам перемещаться по БД.
Дважды щелкните на кнопке Next - появится заготовка обработчика события:
procedure TForm1.NextClick(Sender: TObject);
begin
end;
Теперь добавьте a одну строчку кода так, чтобы процедура выглядела так:
procedure TForm1.NextClick(Sender: TObject);
begin
Table1.Next;
end;
Повторите те же самые действия с кнопкой Prior, так, чтобы функция связанная с ней выглядела так:
procedure TForm1.PriorClick(Sender: TObject);
begin
Table1.Prior;
end;
Теперь запустите программу, и нажмите на кнопки. Вы увидите, что они легко позволяют Вам перемещаться по записям в таблице.
Теперь добавьте еще две кнопки и назовите их First и Last, как показано на рис.3

Рис.3: Программа со всеми четырьмя кнопками.
Сделайте то же самое для новых кнопок.
procedure TForm1.FirstClick(Sender: TObject);
begin
Table1.First;
end;
procedure TForm1.LastClick(Sender: TObject);
begin
Table1.Last;
end;
Нет ничего более простого чем эти навигационные функции. First перемещает Вас в начало таблицы, Last перемещает Вас в конец таблицы, а Next и Prior перемещают Вас на одну запись вперед или назад.
TDataSet.BOF - read-only Boolean свойство, используется для проверки, находитесь ли Вы в начале таблицы. Свойства BOF возвращает true в трех случаях: После того, как Вы открыли файл; После того, как Вы вызывали TDataSet.First; После того, как вызов TDataSet.Prior не выполняется. Первые два пункта - очевидны. Когда Вы открываете таблицу, Delphi помещает Вас на первую запись; когда Вы вызываете метод First, Delphi также перемещает Вас в начало таблицы. Третий пункт, однако, требует небольшого пояснения: после того, как Вы вызывали метод Prior много раз, Вы могли добраться до начала таблицы, и следующий вызов Prior будет неудачным - после этого BOF и будет возвращать True.
Следующий код показывает самый общий пример использования Prior, когда Вы попадаете к началу a файла:
while not Table.Bof do begin
DoSomething;
Table1.Prior;
end;
В коде, показанном здесь, гипотетическая функция DoSomething будет вызвана сперва на текущей записи и затем на каждой следующей записи (от текущей и до начала таблицы). Цикл будет продолжаться до тех пор, пока вызов Table1.Prior не сможет больше переместить Вас на предыдущую запись в таблице. В этот момент BOF вернет True и программа выйдет из цикла. (Чтобы оптимизировать вышеприведенный код, установите DataSource1.Enabled в False перед началом цикла, и верните его в True после окончания цикла.)
Все сказанное относительно BOF также применимо и к EOF. Другими словами, код, приведенный ниже показывает простой способ пробежать по всем записям в a dataset:
Table1.First;
while not Table1.EOF do begin
DoSomething;
Table1.Next;
end;
Классическая ошибка в случаях, подобных этому: Вы входите в цикл while или repeat, но забываете вызывать Table1.Next:
Table1.First;
repeat
DoSomething;
until Table1.EOF;
Если Вы случайно написали такой код, то ваша машина зависнет, и Вы сможете выйти из цикла только нажав Ctrl-Alt-Del и прервав текущий процесс. Также, этот код мог бы вызвать проблемы, если Вы открыли пустую таблицу. Так как здесь используется цикл repeat, DoSomething был бы вызван один раз, даже если бы нечего было обрабатывать. Поэтому, лучше использовать цикл while вместо repeat в ситуациях подобных этой.
EOF возвращает True в следующих трех случаях: После того, как Вы открыли пустой файл; После того, как Вы вызывали TDataSet.Last; После того, как вызов TDataSet.Next не выполняется. Единственная навигационная процедура, которая еще не упоминалась - MoveBy, которая позволяет Вам переместиться на N записей вперед или назад в таблице. Если Вы хотите переместиться на две записи вперед, то напишите:
MoveBy(2);
И если Вы хотите переместиться на две записи назад, то:
MoveBy(-2);
При использовании этой функции Вы должны всегда помнить, что DataSet - это изменяющиеся объекты, и запись, которая была пятой по счету в предыдущий момент, теперь может быть четвертой или шестой или вообще может быть удалена...
Prior и Next - это простые функции, которые вызывают MoveBy. Поля
В большинстве случаев, когда Вы хотите получить доступ из программы к индивидуальные полям записи, Вы можете использовать одно из следующих свойств или методов, каждый из которых принадлежат TDataSet:
property Fields[Index: Integer];
function FieldByName(const FieldName: string): TField;
property FieldCount;
Свойство FieldCount возвращает число полей в текущей структуре записи. Если Вы хотите программным путем прочитать имена полей, то используйте свойство Fields для доступа к ним:
var
S: String;
begin
S := Fields[0].FieldName;
end;
Если Вы работали с записью в которой первое поле называется CustNo, тогда код показанный выше поместит строку “CustNo” в переменную S. Если Вы хотите получить доступ к имени второго поля в вышеупомянутом примере, тогда Вы могли бы написать:
S := Fields[1].FieldName;
Короче говоря, индекс передаваемый в Fields (начинающийся с нуля), и определяет номер поля к которому Вы получите доступ, т.е. первое поле - ноль, второе один, и так далее.
Если Вы хотите прочитать текущее содержание конкретного поля конкретной записи, то Вы можете использовать свойство Fields или метод FieldsByName. Для того, чтобы найти значение первого поля записи, прочитайте первый элемент массива Fields:
S := Fields[0].AsString;
Предположим, что первое поле в записи содержит номер заказчика, тогда код, показанный выше, возвратил бы строку типа “1021”, “1031” или “2058”. Если Вы хотели получить доступ к этот переменный, как к числовой величине, тогда Вы могли бы использовать AsInteger вместо AsString. Аналогично, свойство Fields включают AsBoolean, AsFloat и AsDate.
Если хотите, Вы можете использовать функцию FieldsByName вместо свойства Fields:
S := FieldsByName(‘CustNo’).AsString;
Как показано в примерах выше, и FieldsByName, и Fields возвращают те же самые данные. Два различных синтаксиса используются исключительно для того, чтобы обеспечить программистов гибким и удобным набором инструментов для программного доступа к содержимому DataSet.
Давайте посмотрим на простом примере, как можно использовать доступ к полям таблицы во время выполнения программы. Создайте новый проект, положите на форму объект TTable, два объекта ListBox и две кнопки - “Fields” и “Values” (см рис.4).
Соедините объект TTable с таблицей CUSTOMER, которая поставляется вместе с Delphi (DBDEMOS), не забудьте открыть таблицу (Active = True).

Рис.4: Программа FLDS показывает, как использовать свойство Fields.
Сделайте Double click на кнопке Fields и создайте a метод который выглядит так:
procedure TForm1.FieldsClick(Sender: TObject);
var
i: Integer;
begin
ListBox1.Clear;
for i := 0 to Table1.FieldCount - 1 do
ListBox1.Items.Add(Table1.Fields[i].FieldName);
end;
Обработчик события начинается с очистки первого ListBox1, затем он проходит через все поля, добавляя их имена один за другим в ListBox1. Заметьте, что цикл показанный здесь пробегает от 0 до FieldCount - 1. Если Вы забудете вычесть единицу из FieldCount, то Вы получите ошибку “List Index Out of Bounds”, так как Вы будете пытаться прочесть имя поля которое не существует.
Предположим, что Вы ввели код правильно, и заполнили ListBox1 именами всех полей в текущей структуре записи.
В Delphi существуют и другие средства которые позволяют Вам получить ту же самую информацию, но это самый простой способ доступа к именам полей в Run Time.
Свойство Fields позволяет Вам получить доступ не только именам полей записи, но также и к содержимому полей. В нашем примере, для второй кнопки напишем:
procedure TForm1.ValuesClick(Sender: TObject);
var
i: Integer;
begin
ListBox2.Clear;
for i := 0 to Table1.FieldCount - 1 do
ListBox2.Items.Add(Table1.Fields[i].AsString);
end;
Этот код добавляет содержимое каждого из полей во второй listbox. Обратите внимание, что вновь счетчик изменяется от нуля до FieldCount - 1.
Свойство Fields позволяет Вам выбрать тип результата написав Fields[N].AsString. Этот и несколько связанных методов обеспечивают a простой и гибкий способ доступа к данным, связанными с конкретным полем. Вот список доступных методов который Вы можете найти в описании класса TField:
property AsBoolean
property AsFloat
property AsInteger
property AsString
property AsDateTime
Всякий раз (когда это имеет смысл), Delphi сможет сделать преобразования. Например, Delphi может преобразовывать поле Boolean к Integer или Float, или поле Integer к String. Но не будет преобразовывать String к Integer, хотя и может преобразовывать Float к Integer. BLOB и Memo поля - специальные случаи, и мы их рассмотрим позже. Если Вы хотите работать с полями Date или DateTime, то можете использовать AsString и AsFloat для доступа к ним.
Как было объяснено выше, свойство FieldByName позволяет Вам получить доступ к содержимому определенного поля просто указав имя этого поля:
S := Table1.FieldByName(‘CustNo’).AsString;
Это - удобная технология, которая имеет несколько преимуществ, когда используется соответствующим образом. Например, если Вы не уверены в местонахождении поля, или если Вы думаете, что структура записи, с которой Вы работаете могла измениться, и следовательно, местонахождение поля не определено. Работа с Данными
Следующие методы позволяют Вам изменить данные, связанные с TTable:
procedure Append;
procedure Insert;
procedure Cancel;
procedure Delete;
procedure Edit;
procedure Post;
Все эти методы - часть TDataSet, они унаследованы и используются TTable и TQuery.
Всякий раз, когда Вы хотите изменить данные, Вы должны сначала перевести DataSet в режим редактирования. Как Вы увидите, большинство визуальных компонент делают это автоматически, и когда Вы используете их, то совершенно не будете об этом заботиться. Однако, если Вы хотите изменить TTable программно, Вам придется использовать вышеупомянутые функции.
Имеется a типичная последовательность, которую Вы могли бы использовать при изменении поля текущей записи:
Table1.Edit;
Table1.FieldByName(‘CustName’).AsString := ‘Fred’;
Table1.Post;
Первая строка переводит БД в режим редактирования. Следующая строка присваивает значение ‘Fred’ полю ‘CustName’. Наконец, данные записываются на диск, когда Вы вызываете Post.
При использовании такого подхода, Вы всегда работаете с записями. Сам факт перемещения к следующей записи автоматически сохраняет ваши данные на диск. Например, следующий код будет иметь тот же самый эффект, что и код показанный выше, плюс этому будет перемещать Вас на следующую запись:
Table1.Edit;
Table1.FieldByName(‘CustNo’).AsInteger := 1234;
Table1.Next;
Общее правило, которому нужно следовать - всякий раз, когда Вы сдвигаетесь с текущей записи, введенные Вами данные будут записаны автоматически. Это означает, что вызовы First, Next, Prior и Last
всегда выполняют Post, если Вы находились в режиме редактирования. Если Вы работаете с данными на сервере и транзакциями, тогда правила, приведенные здесь, не применяются. Однако, транзакции - это отдельный вопрос с их собственными специальными правилами, Вы увидите это, когда прочитаете о них в следующих уроках. Тем не менее, даже если Вы не работаете со транзакциями, Вы можете все же отменить результаты вашего редактирования в любое время, до тех пор, пока не вызвали напрямую или косвенно метод Post. Например, если Вы перевели таблицу в режим редактирования, и изменили данные в одном или более полей, Вы можете всегда вернуть запись в исходное состояние вызовом метода Cancel.
Существуют два метода, названные Append и Insert, который Вы можете использовать всякий раз, когда Вы хотите добавить новую запись в DataSet. Очевидно имеет больше смысла использовать Append для DataSets которые не индексированы, но Delphi не будет генерировать exception если Вы используете Append на индексированной таблице. Фактически, всегда можно использовать и Append, и Insert.
Продемонстрируем работу методов на простом примере. Чтобы создать программу, используйте TTable, TDataSource и TdbGrid. Открыть таблицу COUNTRY. Затем разместите две кнопки на форме и назовите их ‘Insert’ и ‘Delete’. Когда Вы все сделаете, то должна получиться программа, показанная на рис.5

Рис.5: Программа может вставлять и удалять запись из таблицы COUNTRY.
Следующим шагом Вы должен связать код с кнопками Insert и Delete:
procedure TForm1.InsertClick(Sender: TObject);
begin
Table1.Insert;
Table1.FieldByName('Name').AsString := 'Russia';
Table1.FieldByName('Capital').AsString := 'Moscow';
Table1.Post;
end;
procedure TForm1.DeleteClick(Sender: TObject);
begin
Table1.Delete;
end;
Процедура показанная здесь сначала переводит таблицу в режим вставки (новая запись с незаполненными полями вставляется в текущую позицию dataset). После вставки пустой записи, следующим этапом нужно назначить значения одному или большему количеству полей. Существует, конечно, несколько различных путей присвоить эти значения. В нашей программе Вы могли бы просто ввести информацию в новую запись через DBGrid. Или Вы могли бы разместить на форме стандартную строку ввода (TEdit) и затем установить каждое поле равным значению, которое пользователь напечатал в этой строке:
Table1.FieldByName(‘Name’).AsString := Edit1.Text;
Можно было бы использовать компоненты, специально предназначенные для работы с данными в DataSet.
Назначение этой главы, однако, состоит в том, чтобы показать, как вводить данные из программы. Поэтому, в примере вводимая информация скомпилирована прямо в код программы:
Table1.FieldByName('Name').AsString := 'Russia';
Один из интересных моментов в этом примере это то, что нажатие кнопки Insert дважды подряд автоматически вызывает exception ‘Key Violation’. Чтобы исправить эту ситуацию, Вы должны либо удалить текущую запись, или изменять поля Name и Capital вновь созданной записи.
Просматривая код показанный выше, Вы увидите, что просто вставка записи и заполнения ее полей не достаточно для того, чтобы изменить физические данные на диске. Если Вы хотите, чтобы информация записалась на диск, Вы должны вызывать Post.
Если после вызова Insert, Вы решаете отказаться от вставки новой записи, то Вы можете вызвать Cancel. Если Вы сделаете это прежде, чем Вы вызовете Post, то все что Вы ввели после вызова Insert будет отменено, и dataset будет находиться в состоянии, которое было до вызова Insert.
Одно дополнительное свойство, которое Вы должны иметь в виду называется CanModify. Если CanModify возвращает False, то TTable находиться в состоянии ReadOnly. В противном случае CanModify возвращает True и Вы можете редактировать или добавлять записи в нее по желанию. CanModify - само по себе ‘read only’ свойство. Если Вы хотите установить DataSet в состояние только на чтение (Read Only), то Вы должны использовать свойство ReadOnly, не CanModify.
Использование SetKey для поиска в таблице
Для того, чтобы найти некоторую величину в таблице, программист на Delphi может использовать две процедуры SetKey и GotoKey. Обе эти процедуры предполагают, что поле по которому Вы ищете индексировано. Delphi поставляется с демонстрационной программой SEARCH, которая показывает, как использовать эти запросы.
Чтобы создать программу SEARCH, поместите TTable, TDataSource, TDBGrid, TButton, TLabel и TEdit на форму, и расположите их как показано на рис.6. Назовите кнопку Search, и затем соедините компоненты БД так, чтобы Вы видели в DBGrid1 таблицу Customer.

Рис.6: Программа SEARCH позволяет Вам ввести номер заказчика и затем найти его по нажатию кнопки.
Вся функциональность программы SEARCH скрыта в единственном методе, который присоединен к кнопке Search. Эта функция считывает строку, введенную в окно редактора, и ищет ее в колонке CustNo, и наконец помещает фокус на найденной записи. В простейшем варианте, код присоединенный к кнопке Search выглядит так:
procedure TSearchDemo.SearchClick(Sender: TObject);
begin
Table1.SetKey;
Table1.FieldByName(’CustNo’).AsString := Edit1.Text;
Table1.GotoKey;
end;
Первый вызов в этой процедуре установит Table1 в режим поиска. Delphi должен знать, что Вы переключились в режим поиска просто потому, что свойство Fields используется по другому в этом режиме. Далее, нужно присвоить свойству Fields значение, которое Вы хотите найти. Для фактического выполнения поиска нужно просто вызывать Table1.GotoKey.
Если Вы ищете не по первичному индексу файла, тогда Вы должны определить имя индекса, который Вы используете в свойстве IndexName. Например, если таблица Customer имеет вторичный индекс по полю City, тогда Вы должны установить свойство IndexName равным имени индекса. Когда Вы будете искать по этому полю, Вы должны написать:
Table1.IndexName := ’CityIndex’;
Table1.Active := True;
Table1.SetKey;
Table1.FieldByName(’City’).AsString := Edit1.Text;
Table1.GotoKey;
Запомните: поиск не будет выполняться, если Вы не назначите правильно индекс (св-во IndexName). Кроме того, Вы должны обратить внимание, что IndexName - это свойство TTable, и не присутствует в других прямых потомках TDataSet или TDBDataSet.
Когда Вы ищете некоторое значение в БД, всегда существует вероятность того, что поиск окажется неудачным. В таком случае Delphi будет автоматически вызывать exception, но если Вы хотите обработать ошибку сами, то могли бы написать примерно такой код:
procedure TSearchDemo.SearchClick(Sender: TObject);
begin
Cust.SetKey;
Cust.FieldByName('CustNo').AsString:= CustNoEdit.Text;
if not Cust.GotoKey then
raise Exception.CreateFmt('Cannot find CustNo %g',
[CustNo]);
end;
В коде, показанном выше, либо неверное присвоение номера, либо неудача поиска автоматически приведут к сообщению об ошибке ‘Cannot find CustNo %g’.
Иногда требуется найти не точно совпадающее значение, а близкое к нему, для этого следует вместо GotoKey пользоваться методом GotoNearest. Использование фильтров для ограничения числа записей в DataSet Процедура ApplyRange позволяет Вам установить фильтр, который ограничивает диапазон просматриваемых записей. Например, в БД Customers, поле CustNo имеет диапазон от 1,000 до 10,000. Если Вы хотите видеть только те записи, которые имеют номер заказчика между 2000 и 3000, то Вы должны использовать метод ApplyRange, и еще два связанных с ним метода. Данные методы работают только с индексированным полем.
Вот процедуры, которые Вы будете чаще всего использовать при установке фильтров:
procedure SetRangeStart;
procedure SetRangeEnd;
procedure ApplyRange;
procedure CancelRange;
Кроме того, у TTable есть дополнительные методы для управления фильтрами:
procedure EditRangeStart;
procedure EditRangeEnd;
procedure SetRange;
Для использования этих процедур необходимо: Сначала вызвать SetRangeStart и использовать свойство Fields для определения начала диапазона. Затем вызвать SetRangeEnd и вновь использовать свойство Fields для определения конца диапазона. Первые два шага подготавливают фильтр, и теперь все что Вам необходимо, это вызвать ApplyRange, и новый фильтр вступит в силу. Когда нужно прекратить действие фильтра - вызовите CancelRange. Программа RANGE, которая есть среди примеров Delphi, показывает, как использовать эти процедуры. Чтобы создать программу, поместите TTable, TDataSource и TdbGrid на форму. Соедините их так, чтобы Вы видеть таблицу CUSTOMERS из подкаталога DEMOS. Затем поместите два объекта TLabel на форму и назовите их ‘Start Range’ и ‘End Range’. Затем положите на форму два объекта TEdit. Наконец, добавьте кнопки ‘ApplyRange’ и ‘CancelRange’. Когда Вы все выполните, форма имеет вид, как на рис.7

Рис.7: Программа RANGE показывает как ограничивать число записей таблицы для просмотра.
Процедуры SetRangeStart и SetRangeEnd позволяют Вам указать первое и последнее значения в диапазоне записей, которые Вы хотите видеть. Чтобы начать использовать эти процедуры, сначала выполните double-click на кнопке ApplyRange, и создайте процедуру, которая выглядит так:
procedure TForm1.ApplyRangeBtnClick(Sender: TObject);
begin
Table1.SetRangeStart;
if RangeStart.Text <> '' then
Table1. Fields[0].AsString := RangeStart.Text;
Table1.SetRangeEnd;
if RangeEnd.Text <> '' then
Table1.Fields[0].AsString := RangeEnd.Text;
Table1.ApplyRange;
end;
Сначала вызывается процедура SetRangeStart, которая переводит таблицу в режим диапазона (range mode). Затем Вы должны определить начало и конец диапазона. Обратите внимание, что Вы используете свойство Fields для определения диапазона:
Table1.Fields[0].AsString := RangeStart.Text;
Такое использование свойства Fields - это специальный случай, так как синтаксис, показанный здесь, обычно используется для установки значения поля. Этот специальный случай имеет место только после того, как Вы перевели таблицу в режим диапазона, вызвав SetRangeStart.
Заключительный шаг в процедуре показанной выше - вызов ApplyRange. Этот вызов фактически приводит ваш запрос в действие. После вызова ApplyRange, TTable больше не в находится в режиме диапазона, и свойства Fields функционирует как обычно.
Обработчик события нажатия кнопки ‘CancelRange’:
procedure TForm1.CancelRangeBtnClick(Sender: TObject);
begin
Table1.CancelRange;
end; Обновление (Refresh)
Как Вы уже знаете, любая таблица, которую Вы открываете всегда “подвержена изменению”. Короче говоря, Вы должны расценить таблицу скорее как меняющуюся, чем как статическую сущность. Даже если Вы - единственное лицо, использующее данную TTable, и даже если Вы не работаете в сети, всегда существует возможность того, что программа с которой Вы работаете, может иметь два различных пути изменения данных в таблице. В результате, Вы должны всегда знать, необходимо ли Вам обновить вид таблицы на экране.
Функция Refresh связана с функцией Open, в том смысле что она считывает данные, или некоторую часть данных, связанных с данной таблицей. Например, когда Вы открываете таблицу, Delphi считывает данные непосредственно из файла БД. Аналогично, когда Вы Регенерируете таблицу, Delphi считывает данные напрямую из таблицы. Поэтому Вы можете использовать эту функцию, чтобы перепрочитать таблицу, если Вы думаете что она могла измениться. Быстрее и эффективнее, вызывать Refresh, чем вызывать Close и затем Open.
Имейте ввиду, однако, что обновление TTable может иногда привести к неожиданным результатам. Например, если a пользователь рассматривает запись, которая уже была удалена, то она исчезнет с экрана в тот момент, когда будет вызван Refresh. Аналогично, если некий другой пользователь редактировал данные, то вызов Refresh приведет к динамическому изменению данных. Конечно маловероятно, что один пользователь будет изменять или удалять запись в то время, как другой просматривает ее, но это возможно. Закладки (Bookmarks)
Часто бывает полезно отметить текущее местоположение в таблице так, чтобы можно было быстро возвратиться к этому месту в дальнейшем. Delphi обеспечивает эту функциональную возможность посредством трех методов, которые используют понятие закладки.
function GetBookmark: TBookmark;
(устанавливает закладку в таблице)
procedure GotoBookmark(Bookmark: TBookmark);
(переходит на закладку)
procedure FreeBookmark(Bookmark: TBookmark);
(освобождает память)
Как Вы можете видеть, вызов GetBookmark возвращает переменную типа TBookmark. TBookmark содержит достаточное количество информации, чтобы Delphi мог найти местоположение к которому относится этот TBookmark. Поэтому Вы можете просто передавать этот TBookmark функции GotoBookmark, и будете немедленно возвращены к местоположению, связанному с этой закладкой.
Обратите внимание, что вызов GetBookmark распределяет память для TBookmark, так что Вы должны вызывать FreeBookmark до окончания вашей программы, и перед каждой попыткой повторного использования Tbookmark (в GetBookMark).
Создание Связанных Курсоров (Linked cursors) Связанные курсоры позволяют программистам определить отношение один ко многим (one-to-many relationship). Например, иногда полезно связать таблицы CUSTOMER и ORDERS так, чтобы каждый раз, когда пользователь выбирает имя заказчика, то он видит список заказов связанных с этим заказчиком. Иначе говоря, когда пользователь выбирает запись о заказчике, то он может просматривать только заказы, сделанные этим заказчиком. Программа LINKTBL демонстрирует, как создать программу которая использует связанные курсоры. Чтобы создать программу заново, поместите два TTable, два TDataSources и два TDBGrid на форму. Присоедините первый набор таблице CUSTOMER, а второй к таблице ORDERS. Программа в этой стадии имеет вид, показанный на рис.8

Рис.8: Программа LINKTBL показывает, как определить отношения между двумя таблицами.
Следующий шаг должен связать таблицу ORDERS с таблицей CUSTOMER так, чтобы Вы видели только те заказы, которые связанные с текущей записью в таблице заказчиков. В первой таблице заказчик однозначно идентифицируется своим номером - поле CustNo. Во второй таблице принадлежность заказа определяется также номером заказчика в поле CustNo. Следовательно, таблицы нужно связывать по полю CustNo в обоих таблицах (поля могут иметь различное название, но должны быть совместимы по типу). Для этого, Вы должны сделать три шага, каждый из которых требует некоторого пояснения: Установить свойство Table2.MasterSource = DataSource1 Установить свойство Table2.MasterField = CustNo Установить свойство Table2.IndexName = CustNo Если Вы теперь запустите программу, то увидите, что обе таблицы связаны вместе, и всякий раз, когда Вы перемещаетесь на новую запись в таблице CUSTOMER, Вы будете видеть только те записи в таблице ORDERS, которые принадлежат этому заказчику.
Свойство MasterSource в Table2 определяет DataSource от которого Table2 может получить информацию. То есть, оно позволяет таблице ORDERS знать, какая запись в настоящее время является текущей в таблице CUSTOMERS.
Но тогда возникает вопрос: Какая еще информация нужна Table2 для того, чтобы должным образом отфильтровать содержимое таблицы ORDERS? Ответ состоит из двух частей: Требуется имя поля по которому связанны две таблицы. Требуется индекс по этому полю в таблице ORDERS (в таблице ‘многих записей’), которая будет связываться с таблицей CUSTOMER(таблице в которой выбирается ‘одна запись’). Чтобы правильно воспользоваться информацией описанной здесь, Вы должны сначала проверить, что таблица ORDERS имеет нужные индексы. Если этот индекс первичный, тогда не нужно дополнительно указывать его в поле IndexName, и поэтому Вы можете оставить это поле незаполненным в таблице TTable2 (ORDERS). Однако, если таблица связана с другой через вторичный индекс, то Вы должны явно определять этот индекс в поле IndexName связанной таблицы.
В примере показанном здесь таблица ORDERS не имеет первичного индекса по полю CustNo, так что Вы должны явно задать в свойстве IndexName индекс CustNo.
Недостаточно, однако, просто yпомянуть имя индекса, который Вы хотите использовать. Некоторые индексы могут содержать несколько полей, так что Вы должны явно задать имя поля, по которому Вы хотите связать две таблицы. Вы должны ввести имя ‘CustNo’ в свойство Table2.MasterFields. Если Вы хотите связать две таблицы больше чем по одному полю, Вы должны внести в список все поля, помещая символ ‘|’ между каждым:
Table1.MasterFields := ‘CustNo | SaleData | ShipDate’;
В данном конкретном случае, выражение, показанное здесь, не имеет смысла, так как хотя поля SaleData и ShipDate также индексированы, но не дублируются в таблице CUSTOMER. Поэтому Вы должны ввести только поле CustNo в свойстве MasterFields. Вы можете определить это непосредственно в редакторе свойств, или написать код подобно показанному выше. Кроме того, поле (или поля) связи можно получить, вызвав редактор связей - в Инспекторе Объектов дважды щелкните на свойство MasterFields (рис.10)

Рис.10: Редактор связей для построения связанных курсоров.
Важно подчеркнуть, что данная глава охватила только один из нескольких путей, которым Вы можете создать связанные курсоры в Delphi. В главе о запросах будет описан второй метод, который будет обращен к тем кто знаком с SQL.
Основные понятия о TDataSource
Класс TDataSource используется в качестве проводника между TTable или TQuery и компонентами, визуализирующими данные, типа TDBGrid, TDBEdit и TDBComboBox (data-aware components). В большинстве случаев, все, что нужно сделать с DataSource - это указать в свойстве DataSet соответствующий TTable или TQuery. Затем, у data-aware компонента в свойстве DataSource указывается TDataSource, который используется в настоящее время.
TDataSource также имеет свойство Enabled, и оно может быть полезно всякий раз, когда Вы хотите временно отсоединить, например, DBGrid от таблицы или запроса. Эти требуется, например, если нужно программно пройти через все записи в таблице. Ведь, если таблица связана с визуальными компонентами (DBGrid, DBEdit и т.п.), то каждый раз, когда Вы вызываете метод TTable.Next, визуальные компоненты будут перерисовываться. Даже если само сканирование в таблице двух или трех тысяч записей не займет много времени, то может потребоваться значительно больше времени, чтобы столько же раз перерисовать визуальные компоненты. В случаях подобных этому, лучше всего установить поле DataSource.Eabled в False. Это позволит Вам просканировать записи без перерисовки визуальных компонент. Это единственная операция может увеличить скорость в некоторых случаях на несколько тысяч процентов.
Свойство TDataSource.AutoEdit указывает, переходит ли DataSet автоматически в режим редактирования при вводе текста в data-aware объекте. Использование TDataSource для проверки состояния БД:
TDataSource имеет три ключевых события, связанных с состоянием БД
OnDataChange
OnStateChange
OnUpdateData
OnDataChange происходит всякий раз, когда Вы переходите на новую запись, или состояние DataSet сменилось с dsInactive на другое, или начато редактирование. Другими словами, если Вы вызываете Next, Previous, Insert, или любой другой запрос, который должен привести к изменению данных, связанных с текущей записью, то произойдет событие OnDataChange. Если в программе нужно определить момент, когда происходит переход на другую запись, то это можно сделать в обработчике события OnDataChange:
procedure TForm1.DataSource1DataChange(Sender: TObject; Field: TField);
begin
if DataSource1.DataSet.State = dsBrowse then begin
DoSomething;
end;
end;
Событие OnStateChange событие происходит всякий раз, когда изменяется текущее состояние DataSet. DataSet всегда знает, в каком состоянии он находится. Если Вы вызываете Edit, Append или Insert, то TTable знает, что он теперь находится в режиме редактирования (dsEdit или dsInsert). Аналогично, после того, как Вы делаете Post, то TTable знает что данные больше не редактируется, и переключается обратно в режим просмотра (dsBrowse).
Dataset имеет шесть различных возможных состояний, каждое из которых включено в следующем перечисляемом типе:
TDataSetState = (dsInactive, dsBrowse, dsEdit, dsInsert,
dsSetKey, dsCalcFields);
В течение обычного сеанса работы, БД часто меняет свое состояние между Browse, Edit, Insert и другими режимами. Если Вы хотите отслеживать эти изменения, то Вы можете реагировать на них написав примерно такой код:
procedure TForm1.DataSource1StateChange(Sender: TObject);
var
S: String;
begin
case Table1.State of
dsInactive: S := 'Inactive';
dsBrowse: S := 'Browse';
dsEdit: S := 'Edit';
dsInsert: S := 'Insert';
dsSetKey: S := 'SetKey';
dsCalcFields: S := 'CalcFields';
end;
Label1.Caption := S;
end;
OnUpdateData событие происходит перед тем, как данные в текущей записи будут обновлены. Например, OnUpdateEvent будет происходить между вызовом Post и фактическим обновлением информации на диске.
События, генерируемые TDataSource могут быть очень полезны. Иллюстрацией этого служит следующий пример. Эта программа работает с таблицей COUNTRY, и включает TTable, TDataSource, пять TEdit, шесть TLlabel, восемь кнопок и панель. Действительное расположение элементов показано на рис.11. Обратите внимание, что шестой TLabel расположен на панели внизу главной формы.

Рис.11: Программа STATE показывает, как отслеживать текущее состояние таблицы.
Для всех кнопок напишите обработчики, вроде:
procedure TForm1.FirstClick(Sender: TObject);
begin
Table1.First;
end;
В данной программе есть одна маленькая хитрость, которую Вы должны понять, если хотите узнать, как работает программа. Так как есть пять отдельных редакторов TEdit на главной форме, то хотелось бы иметь некоторый способ обращаться к ним быстро и легко. Один простой способ состоит в том, чтобы объявить массив редакторов:
Edits: array[1..5] of TEdit;
Чтобы заполнить массив, Вы можете в событии OnCreate главной формы написать:
procedure TForm1.FormCreate(Sender: TObject);
var
i: Integer;
begin
for i := 1 to 5 do
Edits[i] := TEdit(FindComponent('Edit' + IntToStr(i)));
Table1.Open;
end;
Код показанный здесь предполагает, что первый редактор, который Вы будете использовать назовем Edit1, второй Edit2, и т.д. Существование этого массива позволяет очень просто использовать событие OnDataChange, чтобы синхронизировать содержание объектов TEdit с содержимом текущей записи в DataSet:
procedure TForm1.DataSource1DataChange(Sender: TObject;
Field: TField);
var
i: Integer;
begin
for i := 1 to 5 do
Edits[i].Text := Table1.Fields[i - 1].AsString;
end;
Всякий раз, когда вызывается Table1.Next, или любой другой из навигационных методов, то будет вызвана процедура показанная выше. Это обеспечивает то, что все редакторы всегда содержат данные из текущей записи.
Всякий раз, когда вызывается Post, нужно выполнить противоположное действие, то есть взять информацию из редакторов и поместить ее в текущую запись. Выполнить это действие, проще всего в обработчике события TDataSource.OnUpdateData, которое происходит всякий раз, когда вызывается Post:
procedure TForm1.DataSource1UpdateData(Sender: TObject);
var
i: Integer;
begin
for i := 1 to 5 do
Table1.Fields[i - 1].AsString := Edits[i].Text;
end;
Программа будет автоматически переключатся в режим редактирования каждый раз, когда Вы вводите что-либо в одном из редакторов. Это делается в обработчике события OnKeyDown (укажите этот обработчик ко всем редакторам):
procedure TForm1.Edit1KeyDown(Sender: TObject;
var Key: Word; Shift: TShiftState);
begin
if DataSource1.State <> dsEdit then
Table1.Edit;
end;
Этот код показывает, как Вы можете использовать св-во State DataSource, чтобы определить текущий режим DataSet.
Обновление метки в статусной панели происходит при изменении состояния таблицы:
procedure TForm1.DataSource1StateChange(Sender: TObject);
var
s : String;
begin
case DataSource1.State of
dsInactive : s:='Inactive';
dsBrowse : s:='Browse';
dsEdit : s:='Edit';
dsInsert : s:='Insert';
dsSetKey : s:='SetKey';
dsCalcFields : s:='CalcFields';
end;
Label6.Caption:=s;
end;
Данная программа является демонстрационной и ту же задачу можно решить гораздо проще, если использовать объекты TDBEdit.
Отслеживание состояния DataSet В предыдущей части Вы узнали, как использовать TDataSource, чтобы узнать текущее состоянии TDataSet. Использование DataSource - это простой путь выполнения данной задачи. Однако, если Вы хотите отслеживать эти события без использования DataSource, то можете написать свои обработчики событий TTable и TQuery:
property OnOpen
property OnClose
property BeforeInsert
property AfterInsert
property BeforeEdit
property AfterEdit
property BeforePost
property AfterPost
property OnCancel
property OnDelete
property OnNewRecord
Большинство этих свойств очевидны. Событие BeforePost функционально подобно событию TDataSource.OnUpdateData, которое объяснено выше. Другими словами, программа STATE работала бы точно также, если бы Вы отвечали не на DataSource1.OnUpdateData а на Table1.BeforePost. Конечно, в первом случае Вы должен иметь TDataSource на форме, в то время, как во втором этого не требуется.
Компонент TTable
32 урока по Delphi

Урок 20: Компонент TTable. Создание таблиц
с помощью компонента TTable
Содержание урока 20:
Обзор
Создание таблиц с помощью компонента TTable
Заключение
ex20.zip
Обзор
На этом небольшом уроке мы завершим изучение возможностей создания таблиц. Как Вы помните, мы уже освоили два способа создания таблиц - с помощью утилиты Database Desktop, входящей в поставку Delphi (урок 11) и с помощью SQL-запросов (урок 12), которые можно использовать как в WISQL (Windows Interactive SQL - клиентская часть Local InterBase), так и в компоненте TQuery. Теперь мы рассмотрим, как можно создавать локальные таблицы в режиме выполнения с помощью компонента TTable. Создание таблиц с помощью компонента TTable Для создания таблиц компонент TTable имеет метод CreateTable. Этот метод создает новую пустую таблицу заданной структуры. Данный метод (процедура) может создавать только локальные таблицы формата dBase или Paradox.
Компонент TTable можно поместить на форму в режиме проектирования или создать динамически во время выполнения. В последнем случае перед использованием его необходимо создать, например, с помощью следующей конструкции: var
Table1: TTable;
...
Table1:=TTable.Create(nil);
...
Перед вызовом метода CreateTable необходимо установить значения свойств TableType - тип таблицы DatabaseName - база данных TableName - имя таблицы FieldDefs - массив описаний полей IndexDefs - массив описаний индексов. Свойство TableType имеет тип TTableType и определяет тип таблицы в базе данных. Если это свойство установлено в ttDefault, тип таблицы определяется по расширению файла, содержащего эту таблицу: Расширение .DB или без расширения: таблица Paradox Расширение .DBF : таблица dBASE Расширение .TXT : таблица ASCII (текстовый файл). Если значение свойства TableType не равно ttDefault, создаваемая таблица всегда будет иметь установленный тип, вне зависимости от расширения: ttASCII: текстовый файл ttDBase: таблица dBASE
ttParadox: таблица Paradox. Свойство DatabaseName определяет базу данных, в которой находится таблица. Это свойство может содержать: BDE алиас директорий для локальных БД директорий и имя файла базы данных для Local InterBase локальный алиас, определенный через компонент TDatabase. Свойство TableName определяет имя таблицы базы данных. Свойство FieldDefs (имеющее тип TFieldDefs) для существующей таблицы содержит информацию обо всех полях таблицы. Эта информация доступна только в режиме выполнения и хранится в виде массива экземпляров класса TFieldDef, хранящих данные о физических полях таблицы (т.о. вычисляемые на уровне клиента поля не имеют своего объекта TFieldDef). Число полей определяется свойством Count, а доступ к элементам массива осуществляется через свойство Items: property Items[Index: Integer]: TFieldDef;
При создании таблицы, перед вызовом метода CreateTable, нужно сформировать эти элементы. Для этого у класса TFieldDefs имеется метод Add: procedure Add(const Name: string; DataType: TFieldType; Size: Word; Required: Boolean);
Параметр Name, имеющий тип string, определяет имя поля. Параметр DataType (тип TFieldType) обозначает тип поля. Он может иметь одно из следующих значений, смысл которых ясен из их наименования: TFieldType = (ftUnknown, ftString, ftSmallint, ftInteger, ftWord, ftBoolean, ftFloat, ftCurrency, ftBCD, ftDate, ftTime, ftDateTime, ftBytes, ftVarBytes, ftBlob, ftMemo,
ftGraphic); Параметр Size (тип word) представляет собой размер поля. Этот параметр имеет смысл только для полей типа ftString, ftBytes, ftVarBytes, ftBlob, ftMemo, ftGraphic, размер которых может сильно варьироваться. Поля остальных типов всегда имеют строго фиксированный размер, так что данный параметр для них не принимается во внимание. Четвертый параметр - Required - определяет, может ли поле иметь пустое значение при записи в базу данных. Если значение этого параметра - true, то поле является “требуемым”, т.е. не может иметь пустого значения. В противном случае поле не является “требуемым” и, следовательно, допускает запись значения NULL. Отметим, что в документации по Delphi и online-справочнике допущена ошибка - там отсутствует упоминание о четвертом параметре для метода Add.
Если Вы желаете индексировать таблицу по одному или нескольким полям, используйте метод Add для свойства IndexDefs, которое, как можно догадаться, также является объектом, т.е. экземпляром класса TIndexDefs. Свойство IndexDefs для существующей таблицы содержит информацию обо всех индексах таблицы. Эта информация доступна только в режиме выполнения и хранится в виде массива экземпляров класса TIndexDef, хранящих данные об индексах таблицы. Число индексов определяется свойством Count, а доступ к элементам массива осуществляется через свойство Items: property Items[Index: Integer]: TIndexDef;
Метод Add класса TIndexDefs имеет следующий вид: procedure Add(const Name, Fields: string;
Options: TIndexOptions);
Параметр Name, имеющий тип string, определяет имя индекса. Параметр Fields (также имеющий тип string) обозначает имя поля, которое должно быть индексировано, т.е. имя индексируемого поля. Составной индекс, использующий несколько полей, может быть задан списком имен полей, разделенных точкой с запятой “;”, например: ‘Field1;Field2;Field4’. Последний параметр - Options - определяет тип индекса. Он может иметь набор значений, описываемых типом TIndexOptions: TIndexOptions = set of (ixPrimary, ixUnique, ixDescending,
ixCaseInsensitive, ixExpression);
Поясним эти значения. ixPrimary обозначает первичный ключ, ixUnique - уникальный индекс, ixDescending - индекс, отсортированный по уменьшению значений (для строк - в порядке, обратном алфавитному), ixCaseInsensitive - индекс, “нечувствительный” к регистру букв, ixExpression - индекс по выражению. Отметим, что упоминание о последнем значении также отсутствует в документации и online-справочнике. Опция ixExpression позволяет для таблиц формата dBase создавать индекс по выражению. Для этого достаточно в параметре Fields указать желаемое выражение, например: 'Field1*Field2+Field3'. Вообще говоря, не все опции индексов применимы ко всем форматам таблиц. Ниже мы приведем список допустимых значений для таблиц dBase и Paradox:
Опции индексов dBASE Paradox ---------------------------------------
ixPrimary ь
ixUnique ь ь
ixDescending ь ь
ixCaseInsensitive ь
ixExpression ь
Необходимо придерживаться указанного порядка применения опций индексов во избежание некорректной работы. Следует отметить, что для формата Paradox опция ixUnique может использоваться только вместе с опцией ixPrimary (см. пример на диске - рис. ошибка! текст указанного стиля в документе отсутствует.-a).
Итак, после заполнения всех указанных выше свойств и вызова методов Add для FieldDefs и IndexDefs необходимо вызвать метод класса TTable - CreateTable: with Table1 do
begin
DatabaseName:='dbdemos';
TableName:='mytest';
TableType:=ttParadox;
{Создать поля}
with FieldDefs do
begin
Add('Surname', ftString, 30, true);
Add('Name', ftString, 25, true);
Add('Patronymic', ftString, 25, true);
Add('Age', ftInteger, 0, false);
Add('Weight', ftFloat, 0, false);
end;
{Сгенерировать индексы}
with IndexDefs do
begin
Add('I_Name', 'Surname;Name;Patronymic',
[ixPrimary, ixUnique]);
Add('I_Age', 'Age', [ixCaseInsensitive]);
end;
CreateTable;
end;

Options: TIndexOptions);
При этом для метода AddIndex справедливы все замечания по поводу записи полей и опций индексов, сделанные выше.
Заключение Итак, мы познакомились с еще одним способом создания таблиц - способом, использующим метод CreateTable класса TTable. Использование данного способа придаст Вашему приложению максимальную гибкость, и Вы сможете строить локальные таблицы “на лету”. Сопутствующим методом является метод AddIndex класса TTable, позволяющий создавать индексы для уже существующей таблицы. Подчеркнем еще раз, что данный способ применим только для локальных таблиц. Более общий способ состоит в использовании SQL-запросов, который мы рассматривали на уроке 12.